Validus A dead simple Python data validation library.…
December 1, 2021
Splinter基本用法, python splinter用法, python自动化, Splinter实例, python网络爬虫, python selenium, python selenium框架

文档:https://splinter.readthedocs.io/en/latest/index.html
实例 new tab, new window:
import time
from splinter import Browser
from webdriver_manager.chrome import ChromeDriverManager
driver_name = 'chrome'
browser = Browser(driver_name=driver_name, executable_path=ChromeDriverManager().install(), incognito=True, headless=False)
amazon_homepage ='https://www.amazon.com/'
browser.visit(amazon_homepage)
i = 0
for keyword in ['test', 'test1', 'test2']:
if i>0:
print(i)
#browser.new_tab(amazon_homepage)
browser.execute_script(f"window.open('{amazon_homepage}','_blank');")
#browser.switch_to_window(browser.window_handles[-1])
browser.windows.current = browser.windows[i]
browser.fill('field-keywords', keyword)
browser.find_by_id('nav-search-submit-button').click()
i=i+1
time.sleep(3)
#browser.quit()
为何使用Splinter?
Splinter是现有浏览器之上抽象层自动化工具(如 Selenium, PhantomJS 和 zope.testbrowser )。它具有 高级API ,这使得它很容易去编写Web应用程序的自动化测试。
例如, 用Splinter填写一个表单项:
browser.fill('username', 'janedoe')
在Selenium中, 等效代码会是:
elem = browser.find_element.by_name('username')
elem.send_keys('janedoe')
因为Splinter是一个抽象化层面, 它支持多种抽象化后端。使用Splinter,您可以使用相同的测试代码进行基于浏览器的测试,使用Selenium作为后端,并使用zope.testbrowser作为后端进行“headless”测试(无GUI)。
Splinter 有 Chrome 和 Firefox for 的浏览器测试驱动,还有 zope.testbrowser 和 PhantomJS 用于headless测试.
简单实例:
from splinter import Browser
browser = Browser()
browser.visit('http://google.com')
browser.fill('q', 'splinter - python acceptance testing for web applications')
browser.find_by_name('btnK').click()
if browser.is_text_present('splinter.readthedocs.io'):
print("Yes, the official website was found!")
else:
print("No, it wasn't found... We need to improve our SEO techniques")
browser.quit()
Splinter简介
Splinter是一个开源的工具用来通过python自动化测试web应用,可以使用python启动浏览器并自动操作网页,模拟用户点击、输入。
python安装Splinter模块:
pip install splinter
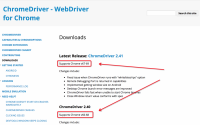
Splinter基于selenium,所以需要有浏览器驱动:Firefox驱动或Chrome驱动, 也可以去selenium官网下载。
python程序中指定使用的浏览器以及浏览器驱动的路径,执行Browser(driver_name=driver_name, executable_path=executable_path)便可自动打开相应的浏览器。
下面示例程序具体操作为打开浏览器,访问登录网站界面,输入用户名、密码,随后点击登录:
driver_name = 'chrome'
executable_path = 'D:\ML\Code\chromedriver.exe'
driver = Browser(driver_name=driver_name, executable_path=executable_path)
driver.driver.set_window_size(1400, 1000)
driver.visit(login_url)
driver.find_by_id('username').fill(username)
driver.find_by_id('password').fill(passwd)
driver.find_by_id('FormLoginBtn').click()
登陆后,browser.cookies.all()中保存了本次登录的cookie信息(dict类型),调用quit()方法即可关闭浏览器。
Splinter可以控制浏览器访问,模拟用户操作,则可以用来做一些自动化操作的简单应用。
Splinter查找标签的基本函数
基本函数:
browser.find_by_css('h1')
browser.find_by_xpath('//h1')
browser.find_by_tag('h1')
browser.find_by_name('name')
browser.find_by_text('Hello World!')
browser.find_by_id('firstheader')
browser.find_by_value('query')
通过id查找页面标签:
find_by_id()
通过name查找页面标签:
find_by_name()
通过text查找页面标签:
# <button class="btn btn-item connect">下一步</button>
find_by_text(u"下一步")
通过option的text查找特定option标签:
<ul class="select2-results__options" role="tree" id="select2--x3-results" aria-expanded="true" aria-hidden="false">
<li class="select2-results__option" role="treeitem" aria-disabled="true">请选择数据库连接</li>
<li class="select2-results__option" id="select2--x3-result-ie1y-35" role="treeitem" aria-selected="true">10.110.181.39_3306_datahub</li>
<li class="select2-results__option select2-results__option--highlighted" id="select2--x3-result-ebx3-34" role="treeitem" aria-selected="false">10.110.181.39_3306_leapid</li>
<li class="select2-results__option" id="select2--x3-result-7jr1-33" role="treeitem" aria-selected="false">10.110.181.39_3306_testDB</li>
</ul>
find_option_by_text("10.110.181.39_3306_leapid")
使用find_by_xpath选取class="keyword"的标签: (xpath 语法和用法)
# <input type="text" class="keyword" placeholder="请输入要查找的表名 ">
find_by_xpath('//*[@class="keyword"]')
使用find_by_xpath选取id中包含default字符串的元素:
<li class="select2-results__option select2-results__option--highlighted" id="select2-batch-dbName-result-42ba-default" role="treeitem" aria-selected="false">default</li>
find_by_xpath('//*[contains(@id, "default")]')
Splinter查找标签的复杂用法
Splinter中标签查找支持链式查找,及可以使用driver.find_by_id().first.find_by_xpath()查找隐藏在特定标签(特征明显)内部的指定标签(特征不明显)。
需要注意的是:
find_by_*()返回的是一个ElementList。- 链式查询只能是在包含关系时,才能查找到隐藏的标签,如2所示。
<li class="db-item" data-catalog="datahub" data-schema="" data-dbname="datahub"> <i class="check dbSelected"></i> <i class="db-icon"></i> <p title="datahub">datahub</p> <a class="getTbl got">-</a> <ul class="tbl"> <li class=" tbl_client_task" data-tblcatalog="datahub" data-tblschema=""> <b>1</b> <i class="check tblSelected "></i> <i class="tbl-icon"></i> <p title="client_task">client_task</p> </li> <li class=" tbl_db_info" data-tblcatalog="datahub" data-tblschema=""> <b>2</b> <i class="check tblSelected "></i> <i class="tbl-icon"></i> <p title="db_info">db_info</p> </li> </ul> </li>1.选取数据库所有表:
driver.find_by_xpath('//*[@data-catalog="'+db+'"]').first.find_by_xpath('.//*[@class="check dbSelected"]').click()2.选择特定数据库中的特定表:
driver.find_by_xpath('//*[@data-catalog="'+db+'"]').first.find_by_xpath('.//*[@class="tbl_'+table+'"]').first.find_by_xpath('.//*[contains(@class,"check tblSelected")]').first.click() # eles = driver.find_by_xpath('//*[@data-catalog="'+db+'"]') # for ele in eles: # ele_ts = ele.find_by_xpath('.//*[@class="tbl_'+table+'"]') # for ele_t in ele_ts: # print(len(ele_t.find_by_xpath('.//*[contains(@class,"check tblSelected")]'))) # ele_t.find_by_xpath('.//*[contains(@class,"check tblSelected")]').first.click()
示例1: test_login
# 需要导入模块: import splinter [as 别名]
# 或者: from splinter import Browser [as 别名]
def test_login(self):
"""Test logging in `testrp` using OIDC"""
browser = Browser(self.webdriver, headless=True)
# Check that user is not logged in
browser.visit('http://testrp:8081')
self.assertTrue(browser.is_text_not_present('Current user:'))
# Perform login
self.perform_login(browser)
# Accept scope
browser.find_by_css('input[name="allow"]').click()
# Check that user is now logged in
self.assertTrue(browser.is_text_present('Current user:'))
示例2: test_logout
# 需要导入模块: import splinter [as 别名]
# 或者: from splinter import Browser [as 别名]
def test_logout(self):
"""Test logout functionality of OIDC lib"""
browser = Browser(self.webdriver, headless=True)
# Check that user is not logged in
browser.visit('http://testrp:8081')
self.assertTrue(browser.is_text_not_present('Current user:'))
self.perform_login(browser)
# Accept scope
browser.find_by_css('input[name="allow"]').click()
# Check that user is now logged in
self.assertTrue(browser.is_text_present('Current user:'))
self.perform_logout(browser)
# Check that user is now logged out
self.assertTrue(browser.is_text_not_present('Current user:'))
示例3: __init__
# 需要导入模块: import splinter [as 别名]
# 或者: from splinter import Browser [as 别名]
def __init__(self):
"""Initiate object with default encoding and other required data."""
# Expect some weird characters from fuzz lists, make encoding UTF-8
reload(sys)
sys.setdefaultencoding('utf8')
# All potential XSS findings
self.xss_links = []
# Fuzzy string matching partials list
self.xss_partials = []
# Keep index of screens for log files
self.screen_index = ""
# Get user args and store
self.user_args = self.parse_args()
# PhantomJS browser
self.browser = Browser("phantomjs")
示例4: __init__
# 需要导入模块: import splinter [as 别名]
# 或者: from splinter import Browser [as 别名]
def __init__(self):
self.captcha_element = None
self.browser = splinter.Browser()
self.neural_net = nn.NeuralNetwork(weights_file=config['weights_path'])
self.num_correct = 0
self.num_guesses = 0
self.old_captcha_urls = []
示例5: 12306自动订票
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
Usage:
python hack12306.py [-c] <configpath>
Options:
-h,--help 显示帮助菜单
-c 指定config.ini绝对路径
Example:
python hack12306.py -c /usr/local/services/config.ini
或者
python hack12306.py
"""
from splinter.browser import Browser
from configparser import ConfigParser
from time import sleep
import traceback
import time, sys
import codecs
import argparse
import os
import time
import string
class hackTickets(object):
"""docstring for hackTickets"""
"""读取配置文件"""
def readConfig(self, config_file='config.ini'):
print("加载配置文件...")
# 补充文件路径,获得config.ini的绝对路径,默认为主程序当前目录
path = os.path.join(os.getcwd(), config_file)
cp = ConfigParser()
try:
# 指定读取config.ini编码格式,防止中文乱码(兼容windows)
cp.readfp(codecs.open(config_file, "r", "utf-8-sig"))
except IOError as e:
print(u'打开配置文件"%s"失败, 请先创建或者拷贝一份配置文件config.ini' % (config_file))
input('Press any key to continue')
sys.exit()
# 登录名
self.username = cp.get("login", "username")
# 密码
self.passwd = cp.get("login", "password")
# 始发站
starts_city = cp.get("cookieInfo", "starts")
# config.ini配置的是中文,转换成"武汉,WHN",再进行编码
self.starts = self.convertCityToCode(starts_city).encode('unicode_escape').decode("utf-8").replace("\\u", "%u").replace(",", "%2c")
# 终点站
ends_city = cp.get("cookieInfo", "ends");
self.ends = self.convertCityToCode(ends_city).encode('unicode_escape').decode("utf-8").replace("\\u", "%u").replace(",", "%2c")
# 乘车时间
self.dtime = cp.get("cookieInfo", "dtime")
# 车次
orderStr = cp.get("orderItem", "order")
# 配置文件中的是字符串,转换为int
self.order = int(orderStr)
# 乘客名
self.users = cp.get("userInfo", "users").split(",")
# 车次类型
self.train_types = cp.get("trainInfo", "train_types").split(",")
# 发车时间
self.start_time = cp.get("trainInfo", "start_time")
# 网址
self.ticket_url = cp.get("urlInfo", "ticket_url")
self.login_url = cp.get("urlInfo", "login_url")
self.initmy_url = cp.get("urlInfo", "initmy_url")
self.initmy_url_1 = cp.get("urlInfo", "initmy_url_1")
self.buy = cp.get("urlInfo", "buy")
# 席别
seat_type = cp.get("confirmInfo", "seat_type")
self.seatType = self.seatMap[seat_type] if seat_type in self.seatMap else ""
# 是否允许分配无座
noseat_allow = cp.get("confirmInfo", "noseat_allow")
self.noseat_allow = 1 if int(noseat_allow) != 0 else 0
# 浏览器名称:目前使用的是chrome
self.driver_name = cp.get("pathInfo", "driver_name")
# 浏览器驱动(目前使用的是chromedriver)路径
self.executable_path = cp.get("pathInfo", "executable_path")
def loadConfig(self):
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', help='Specify config file, use absolute path')
args = parser.parse_args()
if args.config:
# 使用指定的配置文件
self.readConfig(args.config)
else:
# 使用默认的配置文件config.ini
self.readConfig()
"""
加载映射文件,并将中文"武汉"转换成编码后的格式:“武汉,WHN“
"""
def loadCityCode(self):
print("映射出发地、目的地...")
city_codes = {}
path = os.path.join(os.getcwd(), 'city_code.txt')
with codecs.open(path, "r", "utf-8-sig") as f:
for l in f.readlines():
city = l.split(':')[0]
code = l.split(':')[1].strip()
city_codes[city] = city + "," + code
return city_codes
def convertCityToCode(self, c):
try:
return self.city_codes
except KeyError:
print("转换城市错误,请修改config.ini中starts或者ends值为中文城市名")
return False
"""加载席别编码"""
def loadSeatType(self):
self.seatMap = {
"硬座" : "1",
"硬卧" : "3",
"软卧" : "4",
"一等软座" : "7",
"二等软座" : "8",
"商务座" : "9",
"一等座" : "M",
"二等座" : "O",
"混编硬座" : "B",
"特等座" : "P"
}
def __init__(self):
# 读取城市中文与三字码映射文件,获得转换后到城市信息-- “武汉”: "武汉,WHN"
self.city_codes = self.loadCityCode();
# 加载席别
self.loadSeatType()
# 读取配置文件,获得初始化参数
self.loadConfig();
def login(self):
print("开始登录...")
# 登录
self.driver.visit(self.login_url)
# 自动填充用户名
self.driver.fill("loginUserDTO.user_name", self.username)
# 自动填充密码
self.driver.fill("userDTO.password", self.passwd)
print(u"等待验证码,自行输入...")
# 验证码需要自行输入,程序自旋等待,直到验证码通过,点击登录
while True:
if self.driver.url != self.initmy_url and self.driver.url != self.initmy_url_1:
sleep(1)
else:
break
"""更多查询条件"""
def searchMore(self):
# 选择车次类型
for type in self.train_types:
# 车次类型选择
train_type_dict = {'T': u'T-特快', # 特快
'G': u'GC-高铁/城际', # 高铁
'D': u'D-动车', # 动车
'Z': u'Z-直达', # 直达
'K': u'K-快速' # 快速
}
if type == 'T' or type == 'G' or type == 'D' or type == 'Z' or type == 'K':
print(u'--------->选择的车次类型', train_type_dict[type])
self.driver.find_by_text(train_type_dict[type]).click()
else:
print(u"车次类型异常或未选择!(train_type=%s)" % type)
# 选择发车时间
print(u'--------->选择的发车时间', self.start_time)
if self.start_time:
self.driver.find_option_by_text(self.start_time).first.click()
else:
print(u"未指定发车时间,默认00:00-24:00")
"""填充查询条件"""
def preStart(self):
# 加载查询信息
# 出发地
self.driver.cookies.add({"_jc_save_fromStation": self.starts})
# 目的地
self.driver.cookies.add({"_jc_save_toStation": self.ends})
# 出发日
self.driver.cookies.add({"_jc_save_fromDate": self.dtime})
def specifyTrainNo(self):
count=0
while self.driver.url == self.ticket_url:
# 勾选车次类型,发车时间
self.searchMore();
sleep(0.05)
self.driver.find_by_text(u"查询").click()
count += 1
print(u"循环点击查询... 第 %s 次" % count)
try:
self.driver.find_by_text(u"预订")[self.order - 1].click()
sleep(0.3)
except Exception as e:
print(e)
print(u"还没开始预订")
continue
def buyOrderZero(self):
count=0
while self.driver.url == self.ticket_url:
# 勾选车次类型,发车时间
self.searchMore();
sleep(0.05)
self.driver.find_by_text(u"查询").click()
count += 1
print(u"循环点击查询... 第 %s 次" % count)
try:
for i in self.driver.find_by_text(u"预订"):
i.click()
# 等待0.3秒,提交等待的时间
sleep(0.3)
except Exception as e:
print(e)
print(u"还没开始预订 %s" %count)
continue
def selUser(self):
print(u'开始选择用户...')
for user in self.users:
self.driver.find_by_text(user).last.click()
def confirmStudent(self):
# if self.driver.is_element_present_by_id('content_defaultwarningAlert_id') == True:
if self.driver.is_element_present_by_xpath('//*[@id="content_defaultwarningAlert_id"]') == True:
print(u"关闭提示弹框...")
# self.driver.find_by_xpath('//*[@id="qd_closeDefaultWarningWindowDialog_id"]').click()
self.driver.find_by_id('qd_closeDefaultWarningWindowDialog_id').click()
def confirmOrder(self):
print(u"选择席别...")
if self.seatType:
self.driver.find_by_value(self.seatType).click()
else:
print(u"未指定席别,按照12306默认席别")
def submitOrder(self):
print(u"提交订单...")
sleep(1)
self.driver.find_by_id('submitOrder_id').click()
def confirmSeat(self):
# 若提交订单异常,请适当加大sleep的时间
sleep(1)
print(u"确认选座...")
if self.driver.find_by_text(u"硬座余票<strong>0</strong>张") == None:
self.driver.find_by_id('qr_submit_id').click()
else:
if self.noseat_allow == 0:
self.driver.find_by_id('back_edit_id').click()
elif self.noseat_allow == 1:
self.driver.find_by_id('qr_submit_id').click()
def buyTickets(self):
t = time.clock()
try:
print(u"购票页面开始...")
# 填充查询条件
self.preStart()
# 带着查询条件,重新加载页面
self.driver.reload()
# 预定车次算法:根据order的配置确定开始点击预订的车次,0-从上至下点击,1-第一个车次,2-第二个车次,类推
if self.order != 0:
# 指定车次预订
self.specifyTrainNo()
else:
# 默认选票
self.buyOrderZero()
print(u"开始预订...")
sleep(0.8)
# 选择用户
self.selUser()
# 关闭提示弹框
self.confirmStudent()
# 确认订单
self.confirmOrder()
# 提交订单
self.submitOrder()
# 确认选座
self.confirmSeat()
print(time.clock() - t)
except Exception as e:
print(e)
"""入口函数"""
def start(self):
# 初始化驱动
self.driver=Browser(driver_name=self.driver_name,executable_path=self.executable_path)
# 初始化浏览器窗口大小
self.driver.driver.set_window_size(1400, 1000)
# 登录,自动填充用户名、密码,自旋等待输入验证码,输入完验证码,点登录后,访问 tick_url(余票查询页面)
self.login()
# 登录成功,访问余票查询页面
self.driver.visit(self.ticket_url)
# 自动购买车票
self.buyTickets();
if __name__ == '__main__':
print("===========12306 begin===========")
hackTickets = hackTickets()
hackTickets.start()
示例6: datahub数据自动导入
#!/usr/bin/python
# -*- coding: utf-8 -*-
from time import sleep
from splinter.browser import Browser
import json
import jsonpath
driver_name = 'chrome'
executable_path = 'D:\ML\Code\chromedriver.exe'
driver = Browser(driver_name=driver_name, executable_path=executable_path)
driver.driver.set_window_size(1400, 1000)
login_url='http://node16.sleap.com:8089/leapid-admin/view/login.html?cb=http%3A%2F%2Fnode15.sleap.com%3A2017'
datahub_url='http://node15.sleap.com:2017/'
mysql_href='./db?type=1&dbtype=38'
oracle_href='./db?type=1&dbtype=4'
sqlserver_href='./db?type=1&dbtype=40'
db2_href='./db?type=1&dbtype=44'
postgresql_href='./db?type=1&dbtype=24'
def get_config():
file = open('config.json')
config = json.load(file)
# print(config)
projectList = jsonpath.jsonpath(config, '$..project')
dbTypeList = jsonpath.jsonpath(config, '$..dbType')
hostList = jsonpath.jsonpath(config, '$..host')
dbNameList = jsonpath.jsonpath(config, '$..dbName')
portList = jsonpath.jsonpath(config, '$..port')
userNameList = jsonpath.jsonpath(config, '$..userName')
passWdList = jsonpath.jsonpath(config, '$..passWd')
target_positionList = jsonpath.jsonpath(config, '$..target_position')
conn_nameList = jsonpath.jsonpath(config, '$..conn_name')
source_tableList = jsonpath.jsonpath(config, '$..source_table')
target_dbList = jsonpath.jsonpath(config, '$..target_db')
return projectList,dbTypeList,hostList,dbNameList,portList,userNameList,passWdList,target_positionList,conn_nameList,source_tableList,target_dbList
def login(login_url, username, passwd):
driver.visit(login_url)
driver.find_by_id('username').fill(username)
driver.find_by_id('password').fill(passwd)
driver.find_by_id('FormLoginBtn').click()
def add_db_resources(url, project, dbType, dbHost, port, dbName, username, passwd):
driver.visit(url)
driver.find_by_text(u"资源库信息管理").click()
driver.find_by_text(u"数据库连接信息").click()
driver.find_by_text(u" + 新建资源库信息").click()
# 所属项目
driver.find_by_id('select2-userApp-container').click()
driver.find_by_xpath('//*[@class="select2-search__field"]').fill(project)
driver.find_by_xpath('//*[contains(@class,"select2-results__option")]').click()
# 数据库类型
driver.find_option_by_text(dbType).click()
# 服务器地址
driver.find_by_xpath('//*[@data-key="host"]').fill(dbHost)
# 端口
driver.find_by_xpath('//*[@data-key="port"]').fill(port)
# 数据库dbName
driver.find_by_xpath('//*[@data-key="dbName"]').fill(dbName)
# 用户名
driver.find_by_xpath('//*[@data-key="userName"]').fill(username)
# 密码
driver.find_by_xpath('//*[@data-key="password"]').fill(passwd)
# driver.find_by_text(u"测试连接").click()
driver.find_by_text(u"确定").click()
# driver.find_by_text(u"Hive连接信息").click()
# driver.find_by_text(u"Hdfs连接信息").click()
def import_data_from_mysql(url, href, taskName, project, db_res_name, target_position, conn_name, source_table, target_db):
driver.visit(url)
driver.find_link_by_href(href).click()
# 查找字段为class="taskName"的element
driver.find_by_xpath('//*[@class="taskName"]').fill(taskName)
# 所属项目
driver.find_by_id('select2-userApp-container').click()
driver.find_by_xpath('//*[@class="select2-search__field"]').fill(project)
driver.find_by_xpath('//*[contains(@class,"select2-results__option")]').click()
# 选择数据库连接
driver.find_option_by_text(db_res_name).click()
# 选择目标位置
driver.find_option_by_text(target_position).click()
# 选择连接
driver.find_option_by_text(conn_name).click()
driver.find_by_text(u"下一步").click()
# 解析source_table
sleep(5)
# print(source_table)
if source_table == 'ALL':
# 全选
print('ALL')
driver.find_by_xpath('//*[@class="allSelected check"]').click()
elif isinstance(source_table, list):
# 选择指定数据库中的指定表
# 展开数据库表
driver.find_by_xpath('//*[@class="keyword"]').fill(" ")
sleep(1)
for source in source_table:
# print(source)
db = source["db"]
tables = source["table"]
print('db:', db)
if tables == 'ALL':
# 选择数据库中所有表
driver.find_by_xpath('//*[@data-catalog="'+db+'"]').first.find_by_xpath('.//*[@class="check dbSelected"]').click()
elif isinstance(tables, list):
# print('tables:', tables)
for table in tables:
print(table)
driver.find_by_xpath('//*[@data-catalog="'+db+'"]').first.find_by_xpath('.//*[@class="tbl_'+table+'"]').first.find_by_xpath('.//*[contains(@class,"check tblSelected")]').first.click()
# eles = driver.find_by_xpath('//*[@data-catalog="'+db+'"]')
# for ele in eles:
# ele_ts = ele.find_by_xpath('.//*[@class="tbl_'+table+'"]')
# for ele_t in ele_ts:
# print(len(ele_t.find_by_xpath('.//*[contains(@class,"check tblSelected")]')))
# ele_t.find_by_xpath('.//*[contains(@class,"check tblSelected")]').first.click()
else:
print('source table error!')
sleep(1)
driver.find_by_xpath('//*[@class="move-right"]').click()
driver.find_by_xpath('//*[@class="check allSelected"]').click()
driver.find_by_xpath('//*[@class="batch"]').click()
driver.find_by_id('select2-batch-dbName-container').click()
# 查找id中包含default字段的element
driver.find_by_xpath('//*[contains(@id, "'+target_db+'")]').click()
driver.find_by_text(u"保存").last.click()
sleep(5)
driver.find_by_text(u"下一步").last.click()
sleep(10)
driver.find_by_text(u"开始导入").click()
def simple():
# 登录
login(login_url, 'leapadmin', 'leapadmin')
# 添加资源连接
# project = 'Public_Repository'
project = 'test'
# dbType = 'MySQL'
dbType = 'Oracle'
host = '10.110.181.39'
dbName = 'leapid'
port = '3306'
userName = 'leapid'
passWd = 'leapid-db-pwd'
add_db_resources(datahub_url, project, dbType, host, port, dbName, userName, passWd)
# 导入数据
task_name = 't2'
# 10.110.181.39_3306_leapid
db_res_name = host + "_" + port + "_" + dbName
target_position = 'HIVE'
conn_name = 'LEAP_SYSTEM_HIVE'
source_table = 'ALL'
target_db = 'default'
import_data_from_mysql(datahub_url, mysql_href, task_name, project,db_res_name, target_position, conn_name, source_table, target_db)
def main_function():
# 登录
login(login_url, 'leapadmin', 'leapadmin')
# 获取配置文件中的信息
projectList,dbTypeList,hostList,dbNameList,portList,userNameList,passWdList,target_positionList,conn_nameList,source_tableList,target_dbList = get_config()
size = len(dbTypeList)
for i in range(size):
# 添加资源连接
print("添加第"+str(i)+"个资源连接")
if dbTypeList[i] == 'mysql':
dbType = 'MySQL'
elif dbTypeList[i] == 'oracle':
dbType = 'Oracle'
elif dbTypeList[i] == 'sqlserver':
dbType = 'SQL Server'
elif dbTypeList[i] == 'db2':
dbType = 'DB2'
elif dbTypeList[i] == 'postgresql':
dbType = 'PostgreSQL'
else:
print('dbType error!')
break
print(datahub_url,projectList[i],dbType,hostList[i],portList[i],dbNameList[i],userNameList[i],passWdList[i])
add_db_resources(datahub_url,projectList[i],dbType,hostList[i],portList[i],dbNameList[i],userNameList[i],passWdList[i])
for i in range(size):
# 导入数据
task_name = 'task'+str(i)
db_res_name = hostList[i]+"_"+portList[i]+"_"+dbNameList[i]
if dbTypeList[i] == 'mysql':
href = mysql_href
elif dbTypeList[i] == 'oracle':
href = oracle_href
elif dbTypeList[i] == 'sqlserver':
href = sqlserver_href
elif dbTypeList[i] == 'db2':
href = db2_href
elif dbTypeList[i] == 'postgresql':
href = postgresql_href
else:
print('dbType error!')
break
print("导入第"+str(i)+"个资源连接中所有数据")
print(datahub_url,href,task_name,projectList[i],db_res_name,target_positionList[i],conn_nameList[i],source_tableList[i],target_dbList[i])
import_data_from_mysql(datahub_url,href,task_name,projectList[i],db_res_name,target_positionList[i],conn_nameList[i],source_tableList[i],target_dbList[i])
sleep(10)
if __name__ == "__main__":
# simple()
main_function()
![]()
Related Posts
Python导入模块的几种姿势, Python导入的路径, 绝对导入, 相对导入, 模块加载和路径查找, python import 路径

AI机器学习: 在 macOS 上安装谷歌的TensorFlow, machine learning, 人工智能学习