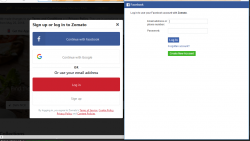
许多网站使用社交媒体登录来简化用户的登录过程。在大多数情况下,如果单击该按钮,则会打开一个新的弹出窗口,用户必须在其中输入用户凭据。可以手动在浏览器中切换窗口并输入所需的凭据以登录。但是,如果使用webdriver进行无人值守的Web访问,则驱动程序不能仅自动切换窗口。我们需要更改驱动程序中的窗口句柄,以便在弹出窗口中输入登录凭据。Selenium具有使用同一驱动程序切换窗口以访问多个窗口的功能。 首先,我们必须从Webdriver获取当前的窗口句柄,这可以通过以下方式完成: driver.current_window_handle 我们需要保存它以获取当前的窗口句柄。弹出窗口出现后,我们必须立即获取所有可用窗口句柄的列表。 driver.window_handles …
December 20, 2019
学会Python+Selenium, 搭建Web自动化框架,自动化处理浏览器任务
在日常工作当中,我们经常会和浏览器打交道,当然就可能会在浏览器上做一些重复、无脑的工作,这篇文章旨在对于这类问题出一个基于脚本的自动化解决方案。
Selenium 库
简要
一句话概括,Selenium 就是一个浏览器自动化测试框架。它支持包括 IE、Chrome、Mozilla Firefox、Mozilla Suite 在内的大多数主流浏览器。当然本文主要讲述的并不是关于它在自动化测试部分方面的运用,该部分在 Selenium 官网和网上各种 Blog 处均有很多也很详细的介绍,这里我们要说的是基于它的浏览器控制能力来演化出的另一个应用方向——自动化处理任务。
快速开始
安装
首先,在拥有 python 环境的 os 中命令行执行
pip install selenium
来安装 Selenium 库。(Mac os 直接安装时可能会出现权限问题,此时尝试命令前面添加sudo,还不行时则需要尝试通过创建 Python 沙盒的方式来安装。)
- 添加
--upgrade或-U以升级安装。 - 添加
--force-reinstall以进行全新安装。
您也可以从以下位置安装seleniumbase git clone:
git clone https://github.com/seleniumbase/SeleniumBase.git cd SeleniumBase/ pip install -r requirements.txt python setup.py install
安装浏览器驱动:
seleniumbase install chromedriver # 或者 安装最新版 # seleniumbase install chromedriver latest # 或者 安装其他浏览器驱动 seleniumbase install chromedriver seleniumbase install geckodriver seleniumbase install edgedriver seleniumbase install iedriver seleniumbase install operadriver
如果以上方法不行的话, 可以考虑手动安装:
其次,下载一个跟自己浏览器和版本对应的 webdriver,然后将该文件配置在环境变量下。比如 Chrome 浏览器的 webdriver 就在这里下载。这里需要注意下载的 webdriver 版本不是越新越好,而是要下载跟自己浏览器版本匹配的。我首次安装时在这里踩过坑。具体查看匹配的方式是打开Chrome => 点击菜单Chrome => 关于Google Chrome,在该界面能看到自己浏览器的版本。然后进入在上面的下载页面找到与自己版本匹配的 webdriver,具体比较的地方在此处

最后测试下是否配置正确,终端打开一个新窗口,输入命令chromedriver -v执行,如果配置没问题,此时便能看到 webdriver 的版本号,如下
➜ ~ cd Documents/libs ➜ libs chromedriver -v ChromeDriver 2.38.552518 (183d19265345f54ce39cbb94cf81ba5f15905011)
快速开始
环境配置完成之后,来通过一个简单的百度搜索然后进入 Selenium 官网的 Demo 来看看 Selenium 的实际运行效果。新建client_selenium.py脚本文件,然后执行添加如下代码
# coding=utf-8
from selenium import webdriver
import time
# 创建一个webdriver实例, 并打开百度页面
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 找到搜索框组件, 并输入关键词"selenium"
element_input = browser.find_element_by_id('kw')
element_input.send_keys('selenium')
# 找到搜索按钮, 并指定点击操作
element_search = browser.find_element_by_xpath('//*[@value="百度一下"]')
element_search.click()
time.sleep(1)
# 找到selenium官网的链接, 并点击进入
element_target = browser.find_element_by_xpath('//*[contains(text(), "Web Browser Automation")]')
element_target.click()
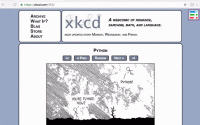
执行该 python 文件后,脚本会通过 webdriver 来去驱动浏览器进行一系列的打开、输入、点击等操作,如下图

常用 api
Selenium 库具有很丰富的 api,但对于只需要写任务处理脚本而言,我们只需要了解一些比较核心高频的 api,下面列举出常用的 api
| 操作 | api | 说明 |
|---|---|---|
| 输入 | send_keys('Hello') |
输入文本 |
| 点击 | click() |
执行点击 |
| 查找元素 | find_element_by_id() |
根据 ID 进查找 |
| 查找元素 | find_element_by_name() |
根据 name 查找 |
| 查找元素 | find_element_by_tag_name() |
根据标签查找 |
| 查找元素 | find_element_by_link_text() |
根据链接文本查找 |
| 查找元素 | find_element_by_class_name() |
根据 class 名查找 |
| 查找元素 | find_elements_by_css_selector() |
根据 css 选择器查找 |
| 查找元素 | find_elements_by_xpath() |
根据 xpath 语法查找 |
可以看到,其中 Selenium 库包含丰富的元素查找相关的 api,找到对应的元素是对该元素进行操作的基础,所以能否快速、便捷、精准的查找到目标元素至关重要。
这里着重强调一下find_elements_by_xpath函数,该函数是基于 XPath 语法规范进行查找元素的,该规范在爬虫开发、浏览器脚本、XML 配置查找等方面的使用时相当高频的。实际上,上面的所有查找方法都可以通过该方法进行替代。
应用
Run a test on Chrome:
cd examples/ pytest my_first_test.py
- 如果未使用,则Chrome是默认浏览器
--browser=BROWSER。 - 在Linux上
--headless是默认行为(不使用GUI运行)。您也可以在任何操作系统上以无头模式运行。如果您的Linux机器具有GUI,并且您想在测试运行时看到网络浏览器,请添加--headed或--gui。
查看my_first_test.py以查看简单测试的外观:
- 默认情况下,CSS选择器用于查找页面元素。
- 以下是您可能在测试中发现的一些常见SeleniumBase方法:
self.open(URL) #导航到网页 self.click(SELECTOR) #单击页面元素 self.update_text(SELECTOR,TEXT) #键入文本(在文本中添加“\n”以按Enter /返回。) self.assert_element(SELECTOR) #声明元素可见 self.assert_text(TEXT) #声明文本可见(具有可选的SELECTOR arg) self.assert_title(PAGE_TITLE) #声明页面标题 self.assert_no_404_errors() #断言页面上文件中没有404错误 self.assert_no_js_errors() #断言页面上没有JavaScript错误(Chrome-Only) self.execute_script(JAVASCRIPT) #执行javascript代码 self.go_back() #导航返回上一个URL self.get_text(SELECTOR) #从选择器中获取文本 self.get_attribute(SELECTOR,ATTRIBUTE) #从选择器中获取特定属性 self.is_element_visible(SELECTOR) #确定元素在页面上是否可见 self.is_text_visible(TEXT) #确定文本在页面上是否可见(可选SELECTOR) self.hover_and_click(HOVER_SELECTOR,CLICK_SELECTOR) #将鼠标悬停在元素上并单击另一个 self.select_option_by_text(DROPDOWN_SELECTOR,OPTION_TEXT) #选择一个下拉选项 self.switch_to_frame(FRAME_NAME) #将 webdriver控件切换到页面上的iframe self.switch_to_default_content() #将 webdriver控件从当前iframe中切换出 self.switch_to_window(WINDOW_NUMBER) #切换到其他窗口/选项卡 self.save_screenshot(FILE_NAME) #保存当前页面的屏幕截图
拓展
用原生 Selenium 的 Api 写过一个应用之后,虽然感觉它的 Api 不算复杂,但对于我们只想写一个自动化脚本而言,还是不够简练,毕竟它的 Api 的初衷是给为了做浏览器自动化测试使用的。
而我想要的效果就是,更简单,尽可能一行代码执行一个 Action,而一个自动化脚本就是包含多个 Action 的一个 Robot。于是就基于 Selenium 库封装了很薄的一层 selenium-robot 库,然后发布到 pypi 仓库里。
以最上面的访问 Selenium 官网的那个 Demo 来比较,用selenium-robot来实现出来的是这样的
from selenium_robot.actions import *
from selenium_robot import Robot
browser = webdriver.Chrome()
Robot(
Open('https://www.baidu.com'),
Input('wd', 'selenium'),
Click('百度一下'),
Click('Web Browser Automation')
).setup(browser)
代码量减少了一半多,最终运行的效果是一样的,对于自动化脚本的开发可以更加便捷、高效。
总结
总的来说,基于上面的 Selenium 库,我们还能开发出很多自动化脚本:
可以把工作中重复的配置操作通过该方式完成,这种工作在运营人员面前应该不少,比如要配置 N 个活动,每天配置广告 Banner,配置公告信息等;
可以结合某些 xml 解析库进行爬虫开发,而且这种爬虫是基于浏览器驱动进行数据爬取的,而非像 Scrapy 等这种基于纯数据角度的爬虫框架一样。人家是模拟浏览器请求,Selenium 模拟都不模拟了,自己干脆直接驱动浏览器,这样几乎不会被反爬工具监测到;
脑洞再大一些,甚至还可以写网页版游戏的外挂等等。
Selenium常用操作
启动和关闭Selenium WebDriver
在Python中,启动Selenium WebDriver(这里以Chrome WebDriver为例)的方法如下:
from selenium import webdriver
# 启动WebDriver
browser = webdriver.Chrome()
# 打开网站
browser.get("https://www.google.com")
# 关闭WebDriver
browser.quit()
其中,使用Chrome WebDriver需要安装Chrome浏览器,并下载Chrome WebDriver,并将Chrome WebDriver文件所在路径加到系统PATH中。如果不方便添加PATH,可以在webdriver.Chrome()中填入绝对路径,如:
browser = webdriver.Chrome("/Users/ntflc/webdriver/chromedriver")
多Tab页面的切换
有的时候,自动化测试需要在多个Tab页面中切换。为了解决页面切换问题,我采用的方法是:新建页面时,记录该Tab页面的handle:
def open_new_tab_and_switch(browser):
# 获取当前Tab页数
handle_cnt = len(browser.window_handles)
# 新建Tab页面
browser.execute_script("window.open('about:blank', '_blank');")
# 跳转到新建的Tab页面
browser.switch_to.window(browser.window_handles[handle_cnt])
# 获取当前Tab页面的handle
current_handle = browser.current_window_handle
# 返回当前Tab页面的handle
return current_handle
每次针对某个Tab页面操作时,使用browser.switch_to.window(handle)跳回对应Tab页面。
iFrame的跳转
刚使用Selenium的时候,经常会遇到一个问题,明明这个元素可见,但就是定位不到。这种时候,可以看看该元素是否在iFrame之中,如果在,需要先跳转到这个iFrame中才行,如:
# 跳转到XPath为xpath的iFrame中 browser.switch_to.frame(browser.find_element_by_xpath(xpath))
同时需要注意的是,如果后续操作不在该iFrame中,记得要跳回原页面。
下拉框的选择
对于下拉框,有时可以粗暴地用send_keys(value)来选择,但很多时候这样并不行,具体方法如下:
from selenium.webdriver.support.ui import Select # 将XPath为xpath的下拉框选择值为value的选项 Select(browser.find_element_by_xpath(xpath).select_by_value(value)
上传文件
对于部分需要涉及到上传文件的地方,比如上传头像,其实原理就是找到对应的input元素,通过send_keys()将文件路径传递,如:
browser.find_element_by_xpath(xpath).send_keys(path_of_file)
其中,xpath为input元素的XPath,path_of_file为文件的路径。
等待
刚接触Selenium的人经常会遇到这样的困惑:为什么我手动一行一行执行的时候正常,写到一个文件中执行就报错?原因是,前一行执行完,但页面却没有加载好,导致执行后一行时,相关元素还没有加载出来。起初,大家可能会想到time.sleep(),但这毕竟不是一个好方法。后来查阅文档发现,Selenium已经提供了等待相关的函数。
我这里总结了我常用的几个:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
# 等待sec秒,直到页面标题为title
try:
WebDriverWait(browser, sec).until(
ec.title_is(title)
)
except Exception as e:
print e
# 等待sec秒,直到Xpath为xpath的元素可见
try:
WebDriverWait(browser, sec).until(
ec.visibility_of_element_located((By.XPATH, xpath))
)
except Exception as e:
print e
# 等待sec秒,直到Xpath为xpath的元素不可见
try:
WebDriverWait(browser, sec).until(
ec.invisibility_of_element_located((By.XPATH, xpath))
)
except Exception as e:
print e
# 等待sec秒,直到Xpath为xpath的元素展现
try:
WebDriverWait(browser, sec).until(
ec.presence_of_element_located((By.XPATH, xpath))
)
except Exception as e:
print e
# 等待sec秒,直到Xpath为xpath的元素中的值为text
try:
WebDriverWait(browser, sec).until(
ec.text_to_be_present_in_element_value((By.XPATH, xpath), text)
)
except Exception as e:
print e
其他常见操作
# 设置WebDriver窗口页面分辨率为1280x720
browser.set_window_size("1280", "720")
# 获取当前页面url
browser.current_url
# 获取当前handle的index
browser.window_handles.index(handle)
# 清空XPath为xpath的元素
browser.find_element_by_xpath(xpath).clear()
# 将val输入到XPath为xpath的元素中
browser.find_element_by_xpath(xpath).send_keys(val)
# 点击XPath为xpath的元素
browser.find_element_by_xpath(xpath).click()
# 获取XPath为xpath的元素的参数key的值
browser.find_element_by_xpath(xpath).get_attribute(key)
# 获取XPath为xpath的元素的的值
browser.find_element_by_xpath(xpath).text
# 点击坐标(x,y)
element = browser.find_element_by_xpath("//body")
action = webdriver.common.action_chains.ActionChains(browser)
action.move_to_element_with_offset(element, x, y)
action.click()
action.perform()
# 获取当前浏览器的User Agent值
browser.execute_script("return navigator.userAgent")
无界面使用Selenium
Selenium WebDriver大多要求有界面,如果通过ssh远程操作,或者在Jenkins上部署,当运行到browser = webdriver.Chrome()的时候,就会报错。解决方法有两类:使用无需界面的WebDriver、模拟生成界面。
无需界面的WebDriver:PhantomJS
PhantomJS是一个脚本化的无界面WebKit,需要下载对应的WebDriver,启动方法为:
browser = webdriver.PhantomJS()
但是,由于个人测试的时候,发现使用PhantomJS WebDriver代替Chrome WebDriver时,部分代码执行出错,因此放弃了。
模拟生成界面
这个是我现在项目使用的方法,可以模拟出一个界面,适用于将项目部署到Jenkins上。具体方法为:
from pyvirtualdisplay import Display # 生成模拟界面,分辨率为1280x720 display = Display(visible=False, size=(1280, 720)) display.start() # 关闭模拟界面 display.stop()
用python+selenium实现UI自动化测试,要有一些HTML和xpth的基础,当然python基础一定是必须要会的。笔者建议花点时间了解下相关基础知识,不至于后面发懵。
一、什么是selenium?
selenium是个强大的工具集。支持快速开发测试自动化,支持在多种浏览器平台上执行测试。支持多开发语言,如:Python、Java、ruby、C#等,本次选择Python3作为开发语言。
二、用python做测试的优点
学习难度小,开发周期短。对目前国内大多数测试人员来说,编码经验不足,python是个很好的入门语言。胶水语言,能与C++, Java, COM, and .NET,Object-C 整合。
测试部门要做单元测试,接口测试,因为人员比例的关系,不可能让测试人员同时掌握多门语言,python可以对C/C++, Java, Object-C进行接口封装后,实现单元测试。语法简约,清晰,减少后期维护的难度。
三、自动化测试框架
一个典型的自动化测试框架一般包括用例管理模块、自动化执行控制器、报表生成模块和日志模块等,这些模块之间不是相互孤立的,而是相辅相成的。

下面来介绍下每个模块的逻辑单元:
用例管理模块
用例管理模块包括用例的添加、修改、删除等操作单元,这些单元也会涉及到用例书写的模式,测试数据的管理、可复用库等
自动化执行控制器
控制器是自动化用例执行的组织模块,主要负责以什么方式去执行用例。比较典型的控制器有用户图形界面(GUI)和”commandline+文件”两种。
报表生成模块
报表生成模块主要负责执行完用例以后生成报表,报表一般以HTML格式居多,信息主要包括用例的执行情况及相应的总结报告。另外还可以添加发送邮件功能。
日志模块
日志模块主要用来记录用例的执行情况,以便于更高效的调查用例失败信息及追踪用例执行情况。
四、自动化框架的设计与实现
方案设计
1、编程代码选择 python3
2、工具selenium + 单元测试框架 unittest
3、编译器: IDE/pycharm
结构设计

cases:
根据功能划分用例管理

用例实现
com


config
edata: 环境配置模块
env.json 、enviroment.yaml 实现城市选择及SIT、UAT环境切换
sdata: 数据配置
各类数据json文件、银行数据、产品信息、个人信息等
elements: 元素定义
locator.py 元素定义、menu 、into_a_management.yaml 等

lib
第三方模块引用, 版本管理

report
管理日志报告
report.xlsx 自动化执行结果生成excel报表

report.xlsx

index.html

需要改进的模块
对于现有实现的测试框架,已经可以满足web对象的自动化需求,但还是有些可以改进提高的地方,比如:
针对部分测试用例是否可以尝试数据驱动
添加屏幕截图功能
封装selenium中By库中的函数,以便更高效的定位页面元素等
结合业界优秀的自动化框架和实践持续改进
五、总结
基于selenium实现的web自动化框架不仅轻量级而且灵活,可以快速的开发自动化测试用例。结合上面的框架设计思路,希望对大家以后的web自动化框架的设计和实现有所帮助
本文:学会Python+Selenium, 搭建Web自动化框架,自动化处理浏览器任务
![]()
Related Posts

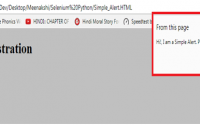
Python:在Selenium中处理警报alert和弹出框Popup,操作alert、confirm、prompt对话框的方法, How to Handle Alert & Pop-up Boxes in Selenium Python
Python: SeleniumBase测试自动化, Web测试框架SeleniumBase, SeleniumBase 实例用法, SeleniumBase 模拟登录, SeleniumBase 入门