
最简单的方法就是直接修改 ~/.bashrc 或者 ~/.bash_aliases文件,添加如下代码: alias python=python3 然后运行 source ~/.bash_aliases #或者 #source…
January 2, 2019
python: JSON文件存储, python解析json, python读取json文件
JSON,全称为JavaScript Object Notation, 也就是JavaScript对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用Python保存数据到JSON文件。
json 模块提供了一种很简单的方式来编码和解码JSON数据。 其中两个主要的函数是 json.dumps() 和 json.loads(), 要比其他序列化函数库如pickle的接口少得多。 下面演示如何将一个Python数据结构转换为JSON:
import json
data = {
'name' : 'ACME',
'shares' : 100,
'price' : 542.23
}
json_str = json.dumps(data)
下面演示如何将一个JSON编码的字符串转换回一个Python数据结构:
data = json.loads(json_str)
如果你要处理的是文件而不是字符串,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据。例如:
# Writing JSON data
with open('data.json', 'w') as f:
json.dump(data, f)
# Reading data back
with open('data.json', 'r') as f:
data = json.load(f)
1. 对象和数组
在JavaScript语言中,一切都是对象。因此,任何支持的类型都可以通过JSON来表示,例如字符串、数字、对象、数组等,但是对象和数组是比较特殊且常用的两种类型,下面简要介绍一下它们。
- 对象:它在JavaScript中是使用花括号
{}包裹起来的内容,数据结构为{key1:value1, key2:value2, ...}的键值对结构。在面向对象的语言中,key为对象的属性,value为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。 - 数组:数组在JavaScript中是方括号
[]包裹起来的内容,数据结构为["java", "javascript", "vb", ...]的索引结构。在JavaScript中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
所以,一个JSON对象可以写为如下形式:
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
}, {
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
JSON可以由以上两种形式自由组合而成,可以无限次嵌套,结构清晰,是数据交换的极佳方式。
2. 读取JSON
Python为我们提供了简单易用的库来实现JSON文件的读写操作,我们可以调用库的loads()方法将JSON文本字符串转为JSON对象,可以通过dumps()方法将JSON对象转为文本字符串。
例如,这里有一段JSON形式的字符串,它是str类型,我们用Python将其转换为可操作的数据结构,如列表或字典:
import json
str = '''
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
}, {
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
'''
print(type(str))
data = json.loads(str)
print(data)
print(type(data))
运行结果如下:
<class 'str'>
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
<class 'list'>
这里使用loads()方法将字符串转为JSON对象。由于最外层是中括号,所以最终的类型是列表类型。
这样一来,我们就可以用索引来获取对应的内容了。例如,如果想取第一个元素里的name属性,就可以使用如下方式:
data[0]['name']
data[0].get('name')
得到的结果都是:
Bob
通过中括号加0索引,可以得到第一个字典元素,然后再调用其键名即可得到相应的键值。获取键值时有两种方式,一种是中括号加键名,另一种是通过get()方法传入键名。这里推荐使用get()方法,这样如果键名不存在,则不会报错,会返回None。另外,get()方法还可以传入第二个参数(即默认值),示例如下:
data[0].get('age')
data[0].get('age', 25)
运行结果如下:
None 25
里我们尝试获取年龄age,其实在原字典中该键名不存在,此时默认会返回None。如果传入第二个参数(即默认值),那么在不存在的情况下返回该默认值。
值得注意的是,JSON的数据需要用双引号来包围,不能使用单引号。例如,若使用如下形式表示,则会出现错误:
import json
str = '''
[{
'name': 'Bob',
'gender': 'male',
'birthday': '1992-10-18'
}]
'''
data = json.loads(str)
运行结果如下:
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 3 column 5 (char 8)
这里会出现JSON解析错误的提示。这是因为这里数据用单引号来包围,请千万注意JSON字符串的表示需要用双引号,否则loads()方法会解析失败。
如果从JSON文本中读取内容,例如这里有一个data.文本文件,其内容是刚才定义的JSON字符串,我们可以先将文本文件内容读出,然后再利用loads()方法转化:
import json
with open('data.json', 'r') as file:
str = file.read()
data = json.loads(str)
print(data)
运行结果如下:
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
3. 输出JSON
另外,我们还可以调用dumps()方法将JSON对象转化为字符串。例如,将上例中的列表重新写入文本:
import json
data = [{
'name': 'Bob',
'gender': 'male',
'birthday': '1992-10-18'
}]
with open('data.json', 'w') as file:
file.write(json.dumps(data))
利用dumps()方法,我们可以将JSON对象转为字符串,然后再调用文件的write()方法写入文本,结果如图所示。
另外,如果想保存JSON的格式,可以再加一个参数indent,代表缩进字符个数。示例如下:
with open('data.json', 'w') as file:
file.write(json.dumps(data, indent=2))
此时写入结果如图所示。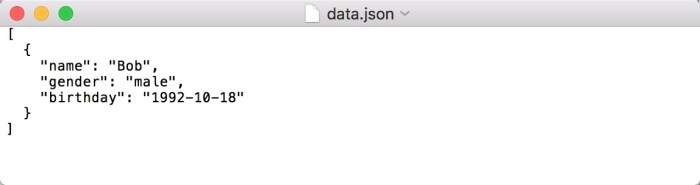
这样得到的内容会自动带缩进,格式会更加清晰。
另外,如果JSON中包含中文字符,会怎么样呢?例如,我们将之前的JSON的部分值改为中文,再用之前的方法写入到文本:
import json
data = [{
'name': '王伟',
'gender': '男',
'birthday': '1992-10-18'
}]
with open('data.json', 'w') as file:
file.write(json.dumps(data, indent=2))
写入结果如图所示。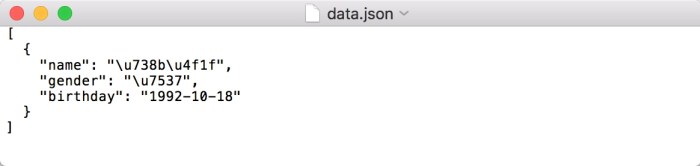
可以看到,中文字符都变成了Unicode字符,这并不是我们想要的结果。
为了输出中文,还需要指定参数ensure_ascii为False,另外还要规定文件输出的编码:
with open('data.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(data, indent=2, ensure_ascii=False))
写入结果如图所示。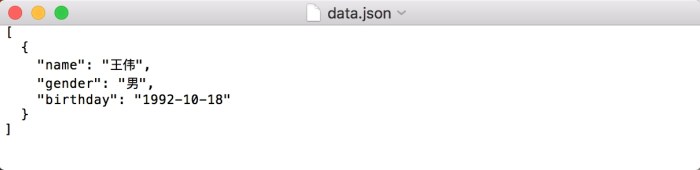
可以发现,这样就可以输出JSON为中文了。
本节中,我们了解了用Python进行JSON文件读写的方法,后面做数据解析时经常会用到,建议熟练掌握。
4. 谈论
JSON编码支持的基本数据类型为 None , bool , int , float 和 str , 以及包含这些类型数据的lists,tuples和dictionaries。 对于dictionaries,keys需要是字符串类型(字典中任何非字符串类型的key在编码时会先转换为字符串)。 为了遵循JSON规范,你应该只编码Python的lists和dictionaries。 而且,在web应用程序中,顶层对象被编码为一个字典是一个标准做法。
JSON编码的格式对于Python语法而已几乎是完全一样的,除了一些小的差异之外。 比如,True会被映射为true,False被映射为false,而None会被映射为null。 下面是一个例子,演示了编码后的字符串效果:
>>> json.dumps(False)
'false'
>>> d = {'a': True,
... 'b': 'Hello',
... 'c': None}
>>> json.dumps(d)
'{"b": "Hello", "c": null, "a": true}'
>>>
如果你试着去检查JSON解码后的数据,你通常很难通过简单的打印来确定它的结构, 特别是当数据的嵌套结构层次很深或者包含大量的字段时。 为了解决这个问题,可以考虑使用pprint模块的 pprint() 函数来代替普通的 print() 函数。 它会按照key的字母顺序并以一种更加美观的方式输出。 下面是一个演示如何漂亮的打印输出Twitter上搜索结果的例子:
>>> from urllib.request import urlopen
>>> import json
>>> u = urlopen('http://search.twitter.com/search.json?q=python&rpp=5')
>>> resp = json.loads(u.read().decode('utf-8'))
>>> from pprint import pprint
>>> pprint(resp)
{'completed_in': 0.074,
'max_id': 264043230692245504,
'max_id_str': '264043230692245504',
'next_page': '?page=2&max_id=264043230692245504&q=python&rpp=5',
'page': 1,
'query': 'python',
'refresh_url': '?since_id=264043230692245504&q=python',
'results': [{'created_at': 'Thu, 01 Nov 2012 16:36:26 +0000',
'from_user': ...
},
{'created_at': 'Thu, 01 Nov 2012 16:36:14 +0000',
'from_user': ...
},
{'created_at': 'Thu, 01 Nov 2012 16:36:13 +0000',
'from_user': ...
},
{'created_at': 'Thu, 01 Nov 2012 16:36:07 +0000',
'from_user': ...
}
{'created_at': 'Thu, 01 Nov 2012 16:36:04 +0000',
'from_user': ...
}],
'results_per_page': 5,
'since_id': 0,
'since_id_str': '0'}
>>>
一般来讲,JSON解码会根据提供的数据创建dicts或lists。 如果你想要创建其他类型的对象,可以给 json.loads() 传递object_pairs_hook或object_hook参数。 例如,下面是演示如何解码JSON数据并在一个OrderedDict中保留其顺序的例子:
>>> s = '{"name": "ACME", "shares": 50, "price": 490.1}'
>>> from collections import OrderedDict
>>> data = json.loads(s, object_pairs_hook=OrderedDict)
>>> data
OrderedDict([('name', 'ACME'), ('shares', 50), ('price', 490.1)])
>>>
下面是如何将一个JSON字典转换为一个Python对象例子:
>>> class JSONObject:
... def __init__(self, d):
... self.__dict__ = d
...
>>>
>>> data = json.loads(s, object_hook=JSONObject)
>>> data.name
'ACME'
>>> data.shares
50
>>> data.price
490.1
>>>
最后一个例子中,JSON解码后的字典作为一个单个参数传递给 __init__() 。 然后,你就可以随心所欲的使用它了,比如作为一个实例字典来直接使用它。
在编码JSON的时候,还有一些选项很有用。 如果你想获得漂亮的格式化字符串后输出,可以使用 json.dumps() 的indent参数。 它会使得输出和pprint()函数效果类似。比如:
>>> print(json.dumps(data))
{"price": 542.23, "name": "ACME", "shares": 100}
>>> print(json.dumps(data, indent=4))
{
"price": 542.23,
"name": "ACME",
"shares": 100
}
>>>
对象实例通常并不是JSON可序列化的。例如:
>>> class Point:
... def __init__(self, x, y):
... self.x = x
... self.y = y
...
>>> p = Point(2, 3)
>>> json.dumps(p)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.3/json/__init__.py", line 226, in dumps
return _default_encoder.encode(obj)
File "/usr/local/lib/python3.3/json/encoder.py", line 187, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/usr/local/lib/python3.3/json/encoder.py", line 245, in iterencode
return _iterencode(o, 0)
File "/usr/local/lib/python3.3/json/encoder.py", line 169, in default
raise TypeError(repr(o) + " is not JSON serializable")
TypeError: <__main__.Point object at 0x1006f2650> is not JSON serializable
>>>
如果你想序列化对象实例,你可以提供一个函数,它的输入是一个实例,返回一个可序列化的字典。例如:
def serialize_instance(obj):
d = { '__classname__' : type(obj).__name__ }
d.update(vars(obj))
return d
如果你想反过来获取这个实例,可以这样做:
# Dictionary mapping names to known classes
classes = {
'Point' : Point
}
def unserialize_object(d):
clsname = d.pop('__classname__', None)
if clsname:
cls = classes[clsname]
obj = cls.__new__(cls) # Make instance without calling __init__
for key, value in d.items():
setattr(obj, key, value)
return obj
else:
return d
下面是如何使用这些函数的例子:
>>> p = Point(2,3)
>>> s = json.dumps(p, default=serialize_instance)
>>> s
'{"__classname__": "Point", "y": 3, "x": 2}'
>>> a = json.loads(s, object_hook=unserialize_object)
>>> a
<__main__.Point object at 0x1017577d0>
>>> a.x
2
>>> a.y
3
>>>
json 模块还有很多其他选项来控制更低级别的数字、特殊值如NaN等的解析。 可以参考官方文档获取更多细节。
5. 解析多层json
1、以豆瓣的API接口为例子,解析返回的json数据
https://api.douban.com/v2/book/1220502
{
"rating":{
"max":10,
"numRaters":16,
"average":"7.3",
"min":0
},
"subtitle":"",
"author":[
"Ranjan Bose",
"武传坤"
],
"pubdate":"2005-1",
"tags":[
{
"count":29,
"name":"信息论",
"title":"信息论"
},
{
"count":22,
"name":"密码学",
"title":"密码学"
},
{
"count":10,
"name":"信息论与编码",
"title":"信息论与编码"
},
{
"count":8,
"name":"计算机",
"title":"计算机"
},
{
"count":5,
"name":"信息学",
"title":"信息学"
},
{
"count":1,
"name":"通信",
"title":"通信"
},
{
"count":1,
"name":"系统信息论",
"title":"系统信息论"
},
{
"count":1,
"name":"欣",
"title":"欣"
}
],
"origin_title":"",
"image":"https://img3.doubanio.com/view/subject/m/public/s1166731.jpg",
"binding":"平装(无盘)",
"translator":[
"武传坤"
],
"catalog":"",
"pages":"206",
"images":{
"small":"https://img3.doubanio.com/view/subject/s/public/s1166731.jpg",
"large":"https://img3.doubanio.com/lpic/s1166731.jpg",
"medium":"https://img3.doubanio.com/view/subject/m/public/s1166731.jpg"
},
"alt":"https://book.douban.com/subject/1220502/",
"id":"1220502",
"publisher":"机械工业出版社",
"isbn10":"7111155343",
"isbn13":"9787111155348",
"title":"信息论、编码与密码学",
"url":"https://api.douban.com/v2/book/1220502",
"alt_title":"",
"author_intro":"",
"summary":"本书集中介绍了信息论、信源编码、信道编码和密码等方面的知识,不仅内容丰富,而且技术深度适当。适合作为高等学校信息安全、电子工程及相关专业信息论和编码课程的教材,从事相关工作的专业技术人员,也能从中受益。
本书利用简短的篇幅对信息论、编码与密码学等信息安全方面的知识,及其所涉及的数学理论进行了精辟论述,内容丰富,避免了太数学化而造成的晦涩难懂:通过翔实的例证由浅入深地阐明理论。
本书特点
对网格编码调制(TCM)进行了详细介绍,以加性白高斯操声(AWGN)和衰退信道为重点。
通过实例阐述了信源编码和信道编码方面的知识。
涵盖了密码学基本理论、密钥和公钥密码学、现代加密标准和最新的研究趋势。",
"series":{
"id":"1163",
"title":"计算机科学丛书"
},
"price":"29.00元"
}
python2的解析代码:
import urllib2 import json html = urllib2.urlopen(r'https://api.douban.com/v2/book/1220562') hjson = json.loads(html.read()) print hjson['id'] print hjson['rating']['max'] print hjson['tags'][0]['name']
python3的解析代码:
import urllib.request
import json
if __name__ == '__main__':
html = urllib.request.urlopen(r'https://api.douban.com/v2/book/1220502')
hjson = json.load(html)
print(hjson)
# print(json.dump(hjson).replace('\'','\"'))
print(hjson['series']['title'])
本文:python: JSON文件存储, python解析json, python读取json文件
![]()
Related Posts
Selenium webdriver 读取认证码, 读取亚马逊Amazon认证码, helium webdriver读取验证码, python读取图形验证码, Solve text captcha, python_anticaptcha
7个用于验证数据的最佳Python库
