pdfminer.six Pdfminer.six是原始PDFMiner的社区维护分支。它是从PDF文档中提取信息的工具。它着重于获取和分析文本数据。Pdfminer.six直接从PDF的源代码中提取页面中的文本。它也可以用来获取文本的确切位置,字体或颜色。 它以模块化方式构建,因此可以轻松替换pdfminer.six的每个组件。您可以实现自己的解释器或渲染设备,以将pdfminer.six的功能用于文本分析的其他目的。 查阅“ 阅读文档”中的完整 文档。 特征 完全用Python编写。 解析,分析和转换PDF文档。 PDF-1.7规范支持。(嗯,差不多)。…
November 17, 2021
Selenium webdriver 读取认证码, 读取亚马逊Amazon认证码, helium webdriver读取验证码, python读取图形验证码, Solve text captcha, python_anticaptcha
1. Selenium webdriver 使用的是:helium,详细教程看这里:helium详细教程, 轻量级Selenium webdriver
安装:pip3 install helium
项目地址:https://github.com/mherrmann/selenium-python-helium
API 文档:https://selenium-python-helium.readthedocs.io/en/latest/api.html
2. 验证码读取使用的是:anti-captcha,
安装:pip install python-anticaptcha
官网:https://anti-captcha.com/
项目地址:https://github.com/ad-m/python-anticaptcha
API 文档:https://python-anticaptcha.readthedocs.io/en/latest/
-
- 验证码读取实例:
import time import requests from os import environ from python_anticaptcha import AnticaptchaClient, ImageToTextTask api_key = '***********' URL = "https://images-na.ssl-images-amazon.com/captcha/bysppkyq/Captcha_dpehjujagv.jpg" EXPECTED_RESULT = "GXLTKF" def process(url): session = requests.Session() client = AnticaptchaClient(api_key) task = ImageToTextTask(session.get(url, stream=True).raw) job = client.createTask(task) job.join() return job.get_captcha_text() if __name__ == "__main__": print("URL: " + URL) print("Result: " + str(process(URL))) print("Expected: " + str(EXPECTED_RESULT)) # print(AnticaptchaClient(api_key).getBalance()) time.sleep(25)更多实例:https://github.com/ad-m/python-anticaptcha/tree/master/examples
- helium + python-anticaptcha 实现自动化 读取亚马逊验证码
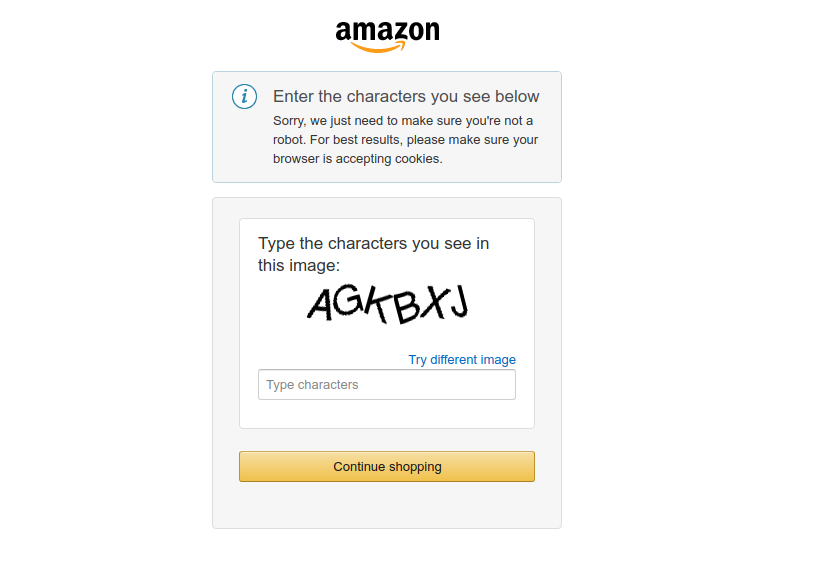
import requests from helium import * from python_anticaptcha import AnticaptchaClient, ImageToTextTask def amazon_page(url): start_chrome(url) if S('#captchacharacters').exists() and S('.a-text-center img').exists(): #pdb.set_trace() image_url = S('.a-text-center img').web_element.get_attribute('src') captcha_text = get_text_from_captcha(image_url) S('#captchacharacters').web_element.clear() S('#captchacharacters').web_element.send_keys(captcha_text) Button('Continue shopping').web_element.click() time.sleep(2) return get_driver().page_source def get_text_from_captcha(image_url): api_key = '************' session = requests.Session() client = AnticaptchaClient(api_key) task = ImageToTextTask(session.get(image_url, stream=True).raw) job = client.createTask(task) job.join() return job.get_captcha_text() if __name__ == "__main__": amazon_page(url)
- 验证码读取实例:
3. 以上是付费版,准确率更高,如果单单想通过亚马逊的验证码,那么还有免费版推荐
Pure Python, lightweight, Pillow-based solver for Amazon’s text captcha.
项目地址:https://github.com/a-maliarov/amazoncaptcha
安装方法:pip install amazoncaptcha
测试页面:https://www.amazon.com/errors/validateCaptcha
实例一 :
from amazoncaptcha import AmazonCaptcha
captcha = AmazonCaptcha('captcha.jpg')
solution = captcha.solve()
# Or: solution = AmazonCaptcha('captcha.jpg').solve()
实例二:
from amazoncaptcha import AmazonCaptcha
from selenium import webdriver
driver = webdriver.Chrome() # This is a simplified example
driver.get('https://www.amazon.com/errors/validateCaptcha')
captcha = AmazonCaptcha.fromdriver(driver)
solution = captcha.solve()
实例三:
from amazoncaptcha import AmazonCaptcha link = 'https://images-na.ssl-images-amazon.com/captcha/usvmgloq/Captcha_kwrrnqwkph.jpg' captcha = AmazonCaptcha.fromlink(link) solution = captcha.solve()
实例四:
from amazoncaptcha import AmazonCaptcha
from selenium import webdriver
driver = webdriver.Chrome() # This is a simplified example
driver.get('https://www.amazon.com/errors/validateCaptcha')
captcha = AmazonCaptcha.fromdriver(driver)
solution = captcha.solve(keep_logs=True)
![]()
Related Posts

Python最好的时间库, Python时间日期工具, Python处理日期和时间, arrow时间库使用详解, Python Arrow 教程, Python3 Arrow 时间日期增强库
Python导入模块的几种姿势, Python导入的路径, 绝对导入, 相对导入, 模块加载和路径查找, python import 路径