在 Node.js 模块库中有很多好用的模块。接下来我们为大家介绍几种常用模块的使用: 序号 模块名 & 描述 1 OS…
August 23, 2016
MySQL入门 (三) : 运算式与函式
运算式(expressions)已经在查询叙述中使用过,例如算数运算与「WHERE」子句中的条件判断。 虽然目前只有讨论查询资料的部份,不过你在任何地方都有可能使用运算式来完成你的工作。 一个运算式中可以包含值(literal values)、运算子和函式,都会在这里讨论它们的细节与应用。
1 值与运算式
不论在执行查询或资料异动的时候,你都可能会使用各种不同种类的值(literal values)来完成你的工作:

不同种类的值会有不同的用法与规定,可以搭配使用的运算子和函式也不一样。 根据资料类型可以分为下列几种:
- 数值:可以用来执行算数运算的数值,包含整数与小数,分为 精确值与近似值两种
- 字串:使用单引号或双引号包围的文字
- 日期/时间:使用单引号或双引号包围的日期或时间
- 空值:使用「NULL」表示的值
- 布林值:「TRUE」或「1」表示「真」,「FALSE」或「0」表示「假」
1.1 数值
数值分为「精确值(exact-value)」与「近似值(approximate-value)」两种。 精确值在使用时不会因为进位而产生差异;使用近似值的时候,可能会因为进位而产生些微的差异。 精确值使用一个明确的数字来表示一个整数或小数数值:
- 整数:没有小数的数字,范围从-9223372036854775808到9223372036854775807
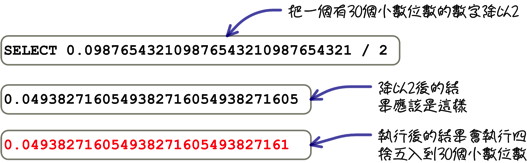
- 小数:包含小数的数字,整数范围与上面一样,小数位数最多可以有30个
一般来说,使用精确值在执行各种算数运算的时候,所得到的结果都不会有误差的问题,你只要特别注意范围就可以了。 例如下列这个比较奇怪的查询需求:
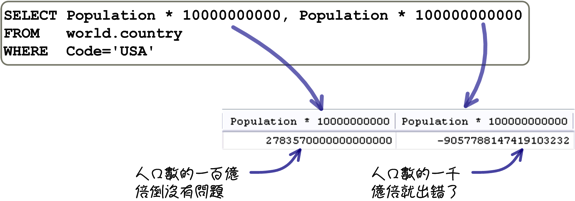
包含小数的数字,在整数部份的限制与整数相同,小数位数会有这样的限制:
近似值的的数字通常称为「科学表示法」,它使用下列的方式来表示一个数值:

这两种表示方式所代表的数值是这样计算的:
- XE+Y,X * 10Y,例如5E+3,代表的数字为5000
- XE-Y,X * 10-Y,例如5E-3,代表的数字为0.005
注:「XE+Y」格式中的「+」可以省略,例如「5E+3」与「5E3」是一样的。
使用近似值来表示一个数值的时候,你一定要牢记它是一个「近似值」,也就是它真正储存的数值可能不是你所看到的。 下列的情况是你比较容易理解的:
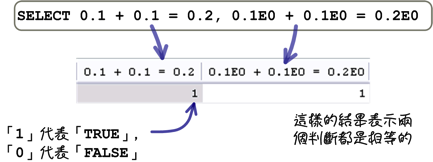
不过下列的状况就会有不一样的结果:

第一个运算值采用精确值的方式,所以它们一定会相等;第二个运算使用近似值的方式,所以它们不一定相等。
1.2 字串值
字串值是以单引号或双引号包围的文字资料,就文字资料来说,你不会拿文字执行加、减、乘、除这类的算数运算。 如果你拿字串来执行算数运算的话,MySQL会先把字串中的内容转换为数字,然后再执行算数运算:
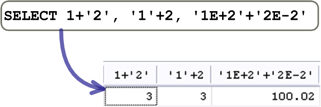
如果字串内容包含不是数值的文字,MySQL在执行转换的时候会出现警告讯息:

字串与字串可以执行连接的运算,就是把一些字串的内容连接起来后,产生一个新的字串。 要执行字串连接的工作,可以使用「||」运算子,这个运算子在条件的判断中是「或」的意思,如果你直接使用「||」运算子连接字串的话:
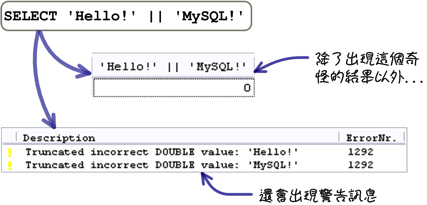
这是因为在预设的设定下,MySQL把「||」运算子当成数值的「或」运算,所以会出现这样的情况;你可以透过设定MySQL的SQL模式,来改变这个预设处理方式:
SET sql_mode = 'PIPES_AS_CONCAT'
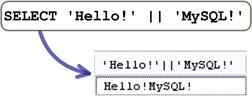
这个设定会把「||」运算子用在字串值的时候,把它当成「连接」运算子:
注:字串的连接也可以使用函式来处理,在这章的后面讨论;另外字串的比较因为跟编码有关,会在后面的章节详细讨论。
1.3 日期与时间值
日期与时间值(temporal values)有下列几种:
- 日期:年年年年-月月-日日,’2007-01-01′
- 日期时间:年年年年-月月-日日时时:分分:秒秒,’2007-01-01 12:00:00′
- 时间:时时:分分:秒秒:’12:00:00′
在日期与时间值中西元年的部份,可以使用四个或两个数字。 如果指定的两个数字是「70」到「99」之间,就代表「1970」到「1999」;如果是「00」到「69」之间,就代表「2000」到「2069」。 日期值中预设的分隔字元是「-」,你也可以使用「/」,所以「2000-1-1」与「2000/1/1」都是正确的日期值。
日期时间资料可以使用在条件的判断外,也可以用来「运算」,不过当然不是数值的算数运算,而是「一个日期的36天后是哪一天」这类的运算,而且只能使用「 +」与「-」的运算。 它的语法是:

语法中的单位可以使用下列表格中的单位关键字:
- YEAR:年
- QUARTER:季
- MONTH:月
- DAY:日
- HOUR:时
- MINUTE:分
- SECOND:秒
注:上列「单位关键字」并没有列出所有的单位关键字,全部的单位关键字请参考MySQL手册「12.5. Date and Time Functions」。
1.4 NULL值
「NULL」值的处理比任何其它型态的值都来得奇怪一些,它也是一个很常见的资料,可以用来表示「未知的资料」;而且它最特别的地方是「NULL值与其它任何值都不一样,包含NULL自己」。
「NULL」是一个SQL关键字,大小写都可以。 你已经知道判断一个栏位资料是否为「NULL」值的时候,跟其它一般资料判断是不一样的;如果算数运算式或比较运算式中有任何「NULL」值的话,结果都会是「NULL」 :
SELECT NULL = NULL, NULL < NULL, NULL != NULL, NULL + 3
上列的查询所得到的结果全部都是「NULL」。 所以在比较「NULL」值的时侯要使用下列的方式:

2 函式
在你在执行查询或维护资料的时候,可能会有下列这个比较特殊的需求:
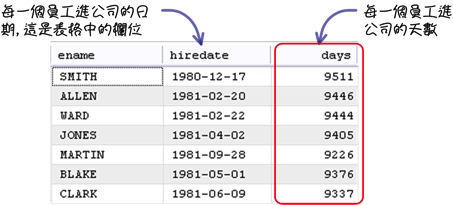
以这样的需求来说,你当然不用自己去计算两个日期之间的天数,MySQL提供许多不同的函式(functions),可以完成这类的需求,不论在执行查询或维护的叙述中,都可以使用这些函式。 函式基本的用法会像这样:
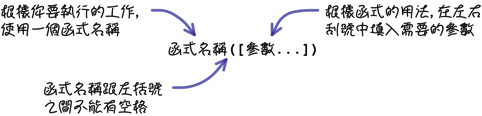
注:MySQL规定函式预设的写法是函式名称和左括号之间不可以有任何空格,否则会造成错误;你可以执行「SET sql_mode=’IGNORE_SPACE’」,这个设定让你可以在函式名称和左括号之间加入空格也不会出错。
以上列「计算两个日期之间的天数」来说,就会在查询叙述中使用到这样的函式:
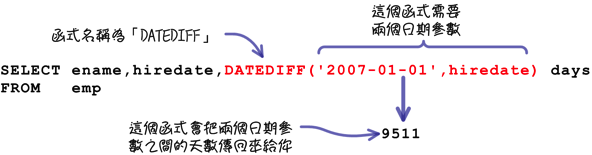
MySQL提供的函式非常多,你不用把每一个函式的名称和用法都背起来,就算是为了参加认证考试也一样。 这个章节只有介绍「部份」函式,并不是全部,所以你在了解这章讨论的函式以后,需要到MySQL参考手册中的「Chapter 12. Functions and Operators」,进一步认识MySQL还有提供哪一些函式。
2.1 字串函式
字串资料的处理是一种很常见的工作,处理字串的函式也非常多,所以这里使用分类的方式来介绍。 下列是处理字串内容的相关函式:
- LOWER(字串):将[字串]转换为小写
- UPPER(字串):将[字串]转换为大写
- LPAD(字串1,长度,字串2):如果[字串1]的长度小于指定的[长度],就在[字串1]左边使用[字串2]补满
- RPAD(字串1,长度,字串2):如果[字串1]的长度小于指定的[长度],就在[字串1]右边使用[字串2]补满
- LTRIM(字串):移除[字串]左边的空白
- RTRIM(字串):移除[字串]右边的空白
- TRIM(字串):移除[字串]左、右的空白
- REPEAT(字串,个数):重复[字串]指定的[个数]
- REPLACE(字串1,字串2,字串3):将[字串1]中的[字串2]替换为[字串3]
「LPAD」与「RPAD」在处理报表资料的时候,很常用来控制报表内容的格式。 例如下列的需求:

使用「LPAD」函式让查询后得到的字串内容向右对齐:

下列是截取字串内容的函式:
- LEFT(字串,长度):传回[字串]左边指定[长度]的内容
- RIGHT(字串,长度):传回[字串]右边指定[长度]的内容
- SUBSTRING(字串,位置):传回[字串]中从指定的[位置]开始到结尾的内容
- SUBSTRING(字串,位置,长度):传回[字串]中从指定的[位置]开始,到指定[长度]的内容
下列是一个测试这些函式的查询叙述:

下列是连接字串的函式:
- CONCAT(参数[,…]):传回所有参数连接起来的字串
- CONCAT_WS(分隔字串,参数[,…]):传回所有参数连接起来的字串,参数之间插入指定的[分隔字串]
你可以使用「||」运算子连接字串,「CONCAT」函式也可以完成同样的需求。 唯一的差异是要先设定「sql_mode」为「PIPES_AS_CONCAT」后,才可以使用「||」运算子连接字串;而「CONCAT」函式不用执行任何设定就可以连接字串。
「CONCAT_WS」函式提供一种比较方便的字串连接功能,例如下列这个使用「||」运算子连接字串的查询叙述:
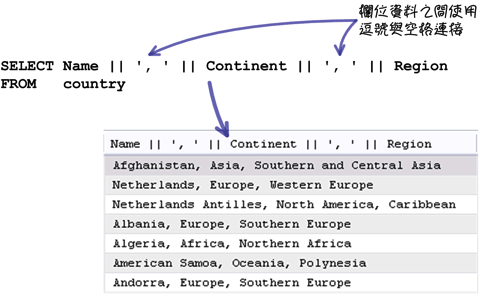
改成使用「CONCAT_WS」函式的话,就会比较简单一些:
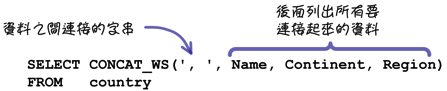
注: 「CONCAT」与「CONCAT_WS」两个函式的参数可以接受任何型态的资料,它们都会把全部的资料转为字串后连接起来;「CONCAT」函式的参数 中如果有「NULL」值,结果会是「NULL」;「CONCAT_WS」函式的参数中如果有「NULL」值,「NULL」值会被忽略。
下列是取得字串资讯的函式:
- LENGTH(字串):传回[字串]的长度(bytes)
- CHAR_LENGTH(字串):传回[字串]的长度(字元个数)
- LOCATE(字串1,字串2):传回[字串1]在[字串2]中的位置,如果[字串2]中没有[字串1]指定的内容就传回0
使用「LENGTH」函式可以完成类似「国家名称长度排行榜」的查询:
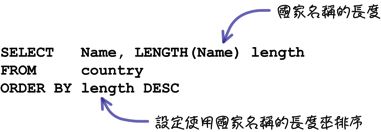
注:「LENGTH」与「CHAR_LENGTH」的差异在「第六章、字元集与资料库」与「第七章、储存引擎与资料型态」中会详细的讨论。
如果有需要的话,你也会搭配许多函式来完成你的工作,例如:
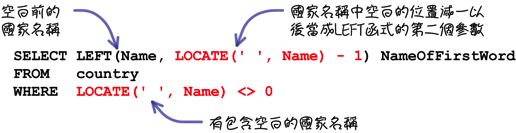
上列的叙述可以查询「名称是一个单字以上的国家」。
2.2 数学函式
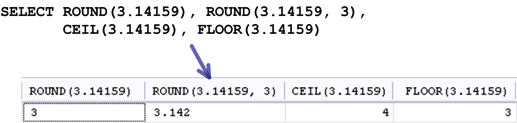
下列是数值舍去与进位的函式:
- ROUND(数字):四舍五入到整数
- ROUND(数字,位数):四舍五入到指定的位数
- CEIL(数字)、CEILING(数字):进位到整数
- FLOOR(数字):舍去所有小数
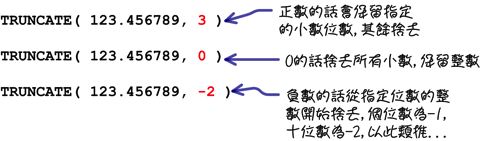
- TRUNCATE(数字,位数):将指定的[数字]舍去指定的[位数]
下列是一个测试这些函式的查询叙述:
在这些函式中,「TRUNCATE」函式的用法会比较不一样:
下列是算数运算的函式:
- PI():圆周率
- POW(数字1,数字2)、POWER(数字,数字2):[数字1]的[数字2]次方
- RAND():乱数
- SQRT(数字):[数字]的平方根
每次使用「RAND」函式的时候,它都会传回一个大于等于0而且小于等于1的小数数字,通常会把它称为「乱数」,这个数值是由MySQL随机产生的。 如果你的叙述中需要一个固定范围内的乱数,可以搭配「RAND」函式套用下列的公式来产生:
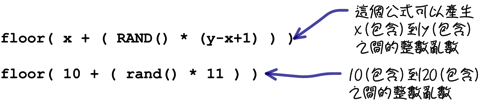
使用「RAND」函式也可以完成「随机查询」的需求:

注:MySQL还有提供的许多不同应用的数学函式,例如三角函式,你可以查询MySQL参考手册中的「12.4.2. Mathematical Functions」。
2.3 日期时间函式
下列是取得日期与时间的函式:
- CURDATE():取得目前日期,相同功能:CURRENT_DATE、CURRENT_DATE()
- CURTIME():取得目前时间,相同功能:CURRENT_TIME、CURRENT_TIME()
- YEAR(日期):传回[日期]的年
- MONTH(日期)数字传回[日期]的月
- DAY(日期):传回[日期]的日,相同功能:DAYOFMONTH()
- MONTHNAME(日期):传回[日期]的月份名称
- DAYNAME(日期):传回[日期]的星期名称
- DAYOFWEEK(日期):传回[日期]的星期,1到7的数字,表示星期日、一、二…
- DAYOFYEAR(日期):传回[日期]的日数,1到366的数字,表示一年中的第几天
- QUARTER(日期):传回[日期]的季,1到4的数字,代表春、夏、秋、冬
- EXTRACT(单位FROM日期/时间):传回[日期]中指定的[单位]资料
- HOUR(时间):传回[时间]的时
- MINUTE(时间):传回[时间]的分
- SECOND(时间):传回[时间]的秒
「CURDATE」与「CURTIME」可以取得目前伺服器的日期与时间,搭配其它函式就可以完成下列的「建国最久的国家排行」查询:
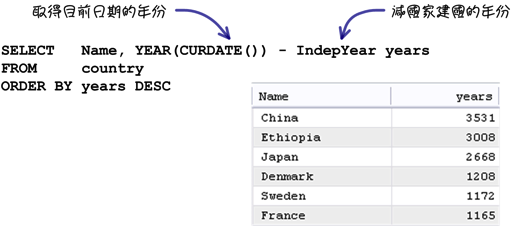
「EXTRACT」函式用来取得日期时间资料的指定「单位」,例如日期中的月份,使用的「单位」与这一章之前在「日期与时间值」中讨论的一样,这个函式让你不用记太多「YEAR」或「MONTH」这类函式的名称:

下列是计算日期与时间的函式:
- ADDDATE(日期,天数):传回[日期]在指定[天数]以后的日期
- ADDDATE(日期, INTERVAL数字单位):传回[日期]在指定[数字]的[单位]以后的日期
- ADDTIME(日期时间, INTERVAL数字单位):传回[日期时间]在指定[数字]的[单位]以后的日期时间
- SUBDATE(日期,天数):传回[日期]在指定[天数]以前的日期
- SUBDATE(日期, INTERVAL数字单位):传回[日期]在指定[数字]的[单位]以前的日期
- SUBTIME(日期时间, INTERVAL数字单位):传回[日期时间]在指定[数字]的[单位]以前的日期时间
- DATEDIFF(日期1,日期2):计算两个日期差异的天数
在计算日期方面的函式,MySQL也提供两种不同的用法:
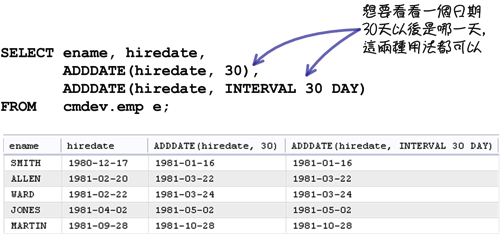
上列函式中使用的「单位」与这一章之前在「日期与时间值」中讨论的一样。
2.4 流程控制函式
在处理一般工作的时候,使用各种SQL叙述与函式,通常就可以完成你的需求;可是在实际的应用上,难免会遇到类似下列这样比较复杂一点的需求:

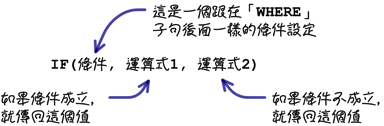
像这种依照条件判断结果而显示不同资料的需求,可以使用下列这个「IF」函式来处理:
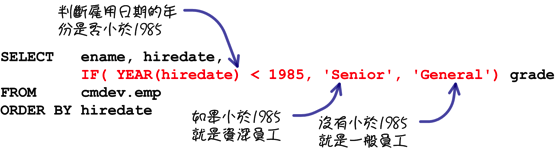
使用「IF」函式可以在查询的时候,依照员工进公司的日期判断是资深或是一般员工:
如果要依照资深员工与一般员工计算不同的奖金,也可以使用「IF」函式来完成:

「IF」函式可以用来判断一个条件「成立」或「不成立」两种状况的需求;但是像下列的需求就不适合使用「IF」函式了:

如果要完成多种条件的判断,就要使用下列的「CASE」语法,它应该不能算是一个函式,因为它的长像实在不像是一个函式:
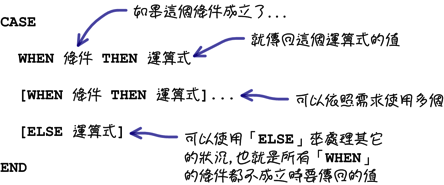
套用上列的语法,就可以判断出所有员工的新资等级:
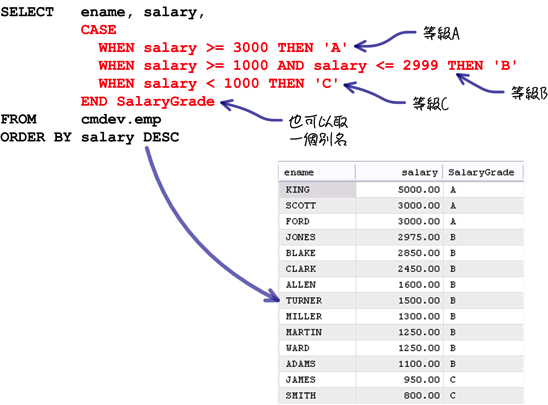
在「CASE」的语法中,要判断一种条件就使用一个「WHEN」来完成;如果有「所有条件以外」的情况要处理的话,就可以使用「ELSE」来处理:

如果要依照员工新资等级计算不同的奖金,也可以使用「CASE」语法来完成这个需求:

「CASE」除了上列介绍的语法外,还有另外一种写法可以处理一些比较特别的需求,例如下列七大洲的名称与缩写对照表:
- Asia:AS
- Europe:EU
- Africa:AF
- Oceania:OA
- Antarctica:AN
- North America:NA
- South America:SA
如果要在SQL叙述中有类似这样的需求,就可以使用下列这种「CASE」的语法:

套用上列的语法就可以完成这样的查询:

以上列的查询来说,你也可以换成这样的写法:
SELECT Name, Continent, CASE WHEN Continent='Asia' THEN 'AS' WHEN Continent='Europe' THEN 'EU' WHEN Continent='Africa' THEN 'AF' WHEN Continent='Oceania' THEN 'OA' WHEN Continent='Antarctica' THEN 'AN' WHEN Continent='North America' THEN 'NA' WHEN Continent='South America' THEN 'SA' END ContinentCode FROM country
经由这样的对照,应该可以很容易看得出来,使用哪一种写法来完成这个查询会好一些。
2.5 其它函式
- IFNULL(参数,运算式):如果[参数]为NULL就传回[运算式]的值;否则传回[参数]的值
- ISNULL(参数):如果[参数]为NULL就传回TRUE;否则传回FALSE
当资料库中有「NULL」资料出现的时候,就可能会发生下列这样奇怪的结果:
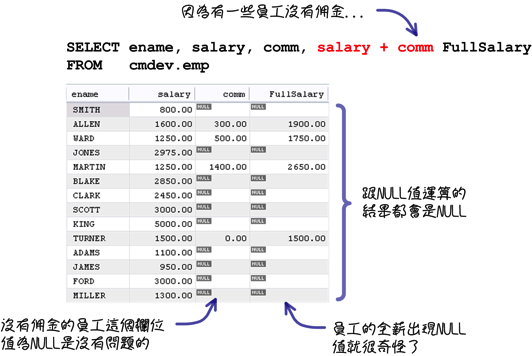
所以要得到正确的结果,就要使用「IFNULL」函式来特别处理NULL值的运算:
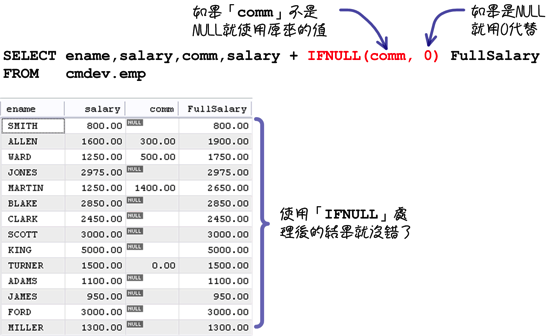
「ISNULL」函式用来判断一个指定的资料是否为「NULL」,它的效果跟之前在「第三章、基础查询、条件比较」中讨论的「IS NULL」和「IS NOT NULL」运算子是一样的,你可以自己决定要使用哪一种来执行判断。
3 群组查询
资料库通常是用来储存庞大数量的资料,这也是它最善长跟主要的工作,所以查询并计算资料的统计分析资讯也是一种很常见的需求:

你也可能会进一步的查询更详细的统计与分析资讯:
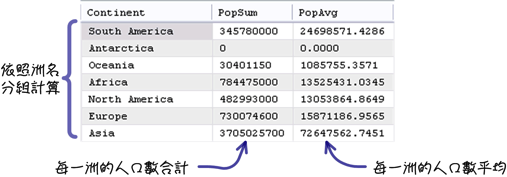
3.1 群组函式
想要完成上列讨论的统计与分析查询,你会用到下列的「群组函式」:
- MAX(运算式):最大值
- MIN(运算式):最小值
- SUM(运算式):合计
- AVG(运算式):平均
- COUNT([DISTINCT]*|运算式):使用「DISTINCT」时,重复的资料不会计算;使用[*]时,计算表格纪录的数量:使用[运算式]时,计算的数量不会包含「 NULL」值
使用上列的群组函式可以很容易的查询需要的统计与分析资讯:

这些函式套用在数值资料时会比较明确一些,把它们用在日期资料也是可以完成「员工最早和最晚进公司的日期」的查询需求:
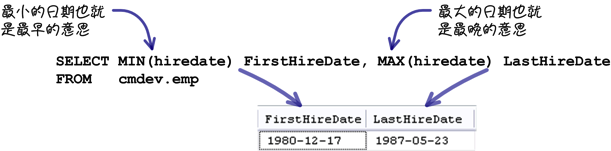
在这些群组函式中,「COUNT」函式的用法会比较不一样:

利用「COUNT」函式的特性,也可以查询一些特别的资讯:

3.2 GROUP_CONCAT函式
「GROUP_CONCAT」函式是比较特别的一个群组函式,它用来将一些字串资料「串接」起来。 在执行一般查询的时候,会根据查询的资料,将许多纪录传回来给你:

使用「GROUP_CONCAT」函式的话,只会回传一笔纪录,这笔纪录包含所有字串资料串接起来的内容:

下列是「GROUP_CONCAT」函式的语法:
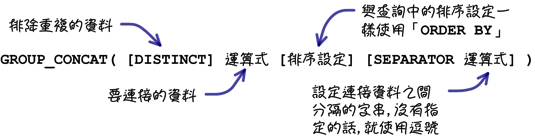
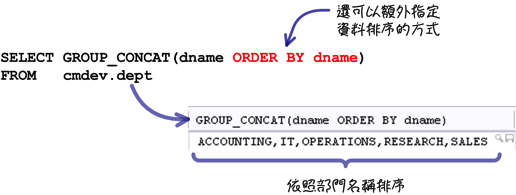
上列的范例是「GROUP_CONCAT」函式最简单的用法,你还可以在函式中使用与「ORDER BY」子句一样的用法来指定资料的排列顺序:
「GROUP_CONCAT」函式连接字串的时候,预设是使用逗号分隔资料,你可以自己指定分隔的字串:

在「GROUP_CONCAT」函式中还可以使用类似在「基础查询、限制查询」中讨论过的「DISTINCT」来排除重复的资料,例如:
在「GROUP_CONCAT」函式中使用「DISTINCT」也会有同样的效果:

3.3 GROUP BY与HAVING子句
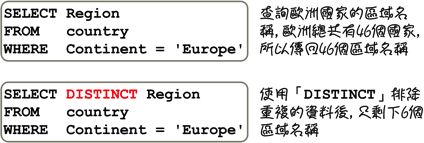
在上列使用群组函式的所有范例中,都是将「FROM」子句中指定的表格当成是一整个「群组」,群组函式所处理的资料是表格中所有的纪录。 如果希望依照指定的资料来计算分组统计与分析资讯,在执行查询的时候,可能会有下列几种不同的结果:
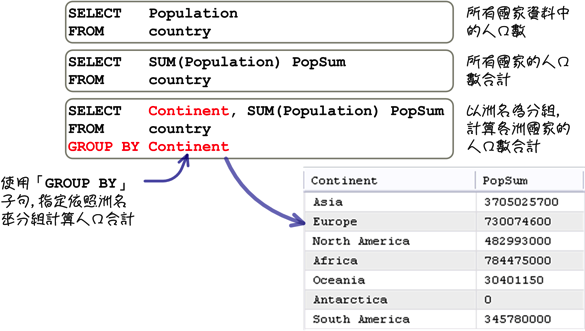
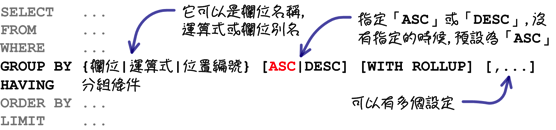
上列的范例使用「GROUP BY」子句指定分组的设定,下列是分组查询中的语法:
「GROUP BY」子句指定是依照你自己的需求来决定的,同样以人口数量合计来说,不同的指定可以得到不同的统计资讯:

使用不同的群组函式,就可以得不同的资讯:
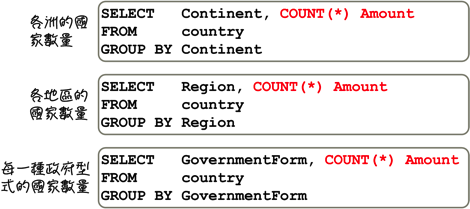
如果需要的话,你可以在一个查询中,一次取得所有需要的统计与分析资讯:

在查询群组统计与分析资讯的时候,你可以指定多个群组设定取得更详细的资讯:
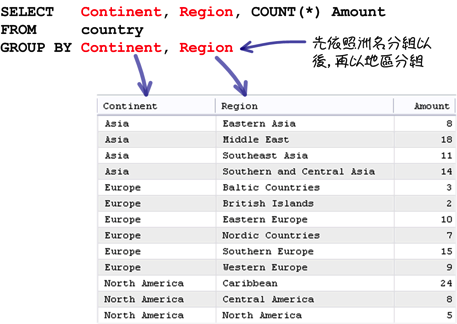
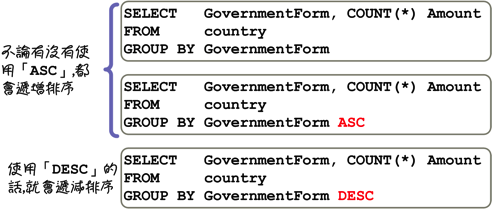
使用「GROUP BY」指定群组的设定以后,回传的群组查询资料都会依照指定的群组排序,预设定排序方式是递增排序,使用「DESC」关键字可以指定排序的方式为递减排序:
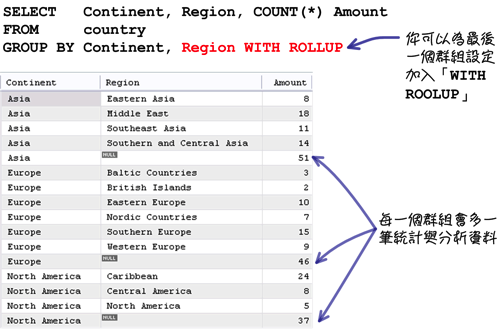
使用「GROUP BY」子句的时候可以搭配「WITH ROLLUP」:

使用「WITH ROLLUP」以后,效果会作用在查询中的每一个群组函式:

在「GROUP BY」子句中有多个群组设定的时候,你可以在最后面加入「WITH ROLLUP」:
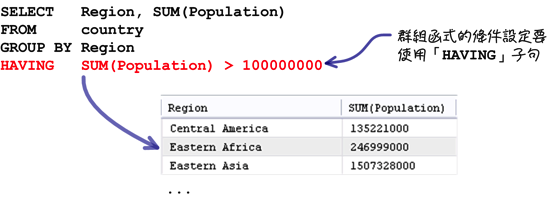
在执行群组查询的时候,一般的条件设定同样使用「WHERE」子句就可以了:

可是以类似上列的查询来说,把查询条件从「亚洲的地区」换成「人口合计大于一亿的地区」,如果还是把条件设定放在「WHERE」子句的话:

包含群组函式的条件设定就一定要放在「HAVING」子句中:
依照需求在执行群组查询的时候,应该不会出现下列的查询叙述:
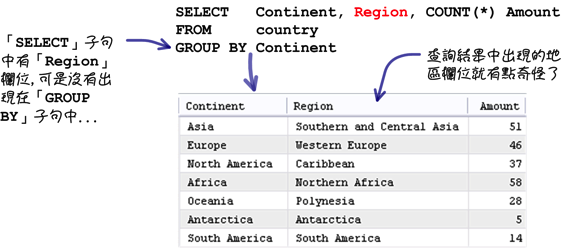
MySQL资料库在执行上列的查询叙述后,并不会产生任何错误,为了预防这样的状况,你可以执行下列的设定:
SET sql_mode = 'ONLY_FULL_GROUP_BY'
在「sql_mode」的设定中加入「ONLY_FULL_GROUP_BY」,表示多了下列的规定:

如果查询叙述违反「ONLY_FULL_GROUP_BY」的规定,就会产生错误讯息:

翻译自: http://www.codedata.com.tw/database/mysql-tutorial-4-expression-function/
更多参考:
![]()

MYSQL: 查询数据库字符串是否被包含在另一个字符串中 Search where column value is within a string

升级到Ubuntu22之后运行 php7.4 , php7.4 in my Apache in Ubuntu 22, Tutorial Install and Configure PHP on Ubuntu 22.04,tu 22.04 run php7.4
Ubuntu/linux 搜狗输入法 隐藏状态栏
About Author
Gideon
One Comment