import logging
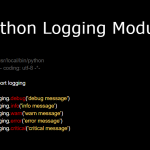
LOG_FILENAME = 'example.log'
logging.basicConfig(filename=LOG_FILENAME,level=logging.DEBUG)
logging.debug('This message should go to the log file')
报错:AttributeError: module ‘logging’ has no attribute ‘debug’,
或者报错:AttributeError: module ‘logging’ has no attribute ‘basi… Read More
Python 是一种面向对象、解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年,Python 源代码同样遵循 GPL(GNU General Public License)协议。Python语法简洁而清晰,具有丰富和强大的类库。
Python3不像2x中酷虎的和服务器模块结构散乱,Python3中把这些打包成为了2个包,就是http与urllib,详解如下:
http会处理所有客户端–服务器http请求的具体细节,其中:
(1)client会处理客户端的部分
(2)server会协助你编写Python web服务器程序
(3)cook… Read More
python中没有其他语言中的三元表达式,不过有类似的实现方法
其他语言中,例如java的三元表达式是这样
int a = 1;
String b = "";
b = a > 1? "执行表达式1":"执行表达式2"
System.out.println(b)
在python中只有类似的替代办法,如果a>b的结果为真,h=”变量1″,如果为假,h=”变量2″
a = 1
b = 2
h = ""
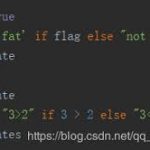
h = "变量1" if a>b else "变量2"
print(h)
也可以用简单的公式,如下,
a = 1
b = 2
h = ""
h = a-b if a>b else a+b
print(h)
&n… Read More
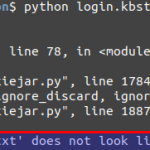
如果遇到
http.cookiejar.LoadError: ‘cookies.txt’ does not look like a Set-Cookie3 (LWP) format file
或
http.cookiejar.LoadError: ‘cookie.txt’ does not look like a Netscape format cookies file
的问题,
那么,原因是cookies.txt文件的内容格式不对!
不知道怎么修改,怎么办呢?
办法:把 CookieJar自己cookie.save()保存下来的文件,用notepad打开来看看,就知道格式了
例如:报错: … Read More