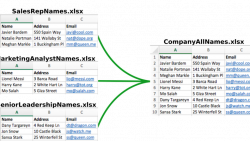
将多个电子表格合并在一起是一项常见的任务。可以通过两种方式进行合并: 追加 -电子表格彼此并置 合并 -根据所选列的相同值水平合并电子表格列 档案 本教程将使用三个文件。您可以通过单击以下链接下载它们:MarketingAnalystNames.xlsx,SalesRepNames.xlsx,SeniorLeadershipNames.xlsx 完整代码 这是追加三个文件的完整代码…
September 7, 2020
Python读写csv/excel文件, Python 读取指定csv行, Python生成csv文件, Python操作csv文件, Python操作CSV和Excel
概述
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列.
CSV操作
csv写入
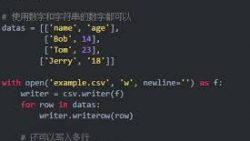
1.写入列表(list)数据
使用 csv.writer 对象
delimiter 指定同一行每个字段的分隔字符。若不指定,默认以英文逗号(,)分隔,在csv文件中显示的是不同单元格,若以其他符号分隔,则显示在csv同一单元格中
import csv
with open(r'e:\zarten.csv', 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile, delimiter=' ')
csv_writer.writerow(['a', 'b', 'c'])
csv_writer.writerow(['d', 'e', 'f'])
csv_writer.close()
或者:
import csv
# 文件头,一般就是数据名
fileHeader = ["name", "score"]
# 假设我们要写入的是以下两行数据
d1 = ["Wang", "100"]
d2 = ["Li", "80"]
# 写入数据
csvFile = open("instance.csv", "w")
writer = csv.writer(csvFile)
# 写入的内容都是以列表的形式传入函数
writer.writerow(fileHeader)
writer.writerow(d1)
writer.writerow(d1)
csvFile.close()
当然,每次写完一行之后,会自动换行,所以,写结果就是我们想要的形式:

需要注意的是最后还有一个空行。
当然,像这种写入多行的情况,可以用更方便的函数 writerows(),还是上面的例子,可以把三行写入的代码,换成以下一行。但是传入的参数是一个列表,每个元素代表需要写入的每行数据。得到的结果和上面是一样的。
writer.writerows([fileHeader, d1, d2])
2.追加
除了直接写入,还能实现追加:还是刚才那个例子,我现在将一行新的数据添加到旧的数据后面,最后写入CSV
import csv
# 新增的数据行,以列表的形式表示
add_info = ["Guo", 150]
# 以添加的形式写入csv,跟处理txt文件一样,设定关键字"a",表追加
csvFile = open("instance.csv", "a")
# 新建对象writer
writer = csv.writer(csvFile)
# 写入,参数还是列表形式
writer.writerow(add_info)
csvFile.close()
这样,就完成了信息的追加。
3. DictReader提供的方便
像上面这种把一个关系型数据库保存为CSV文档,再用Python读取,处理的情况可以说很常见,大多都是先读成字典的形式,再做相应的计算。所以csv库也就提供了能直接将CSV文档读取为字典的函数:DictReader(),当然,也有相应的 DictWriter()
还是上边的例子:
import csv
csvFile = open("instance.csv", "r")
dict_reader = csv.DictReader(csvFile)
for row in dict_reader:
print(row)
输出的结果是这样的:
{'score': '100', 'name': 'Zhang'}
{'score': '80', 'name': 'Wang'}
{'score': '90', 'name': 'Li'}
这个形式就非常清晰明了了,而且还不用费心地写代码将第一行忽略。因为CSV文件第一行,就是(name,score)这一行,能以这种形式输出:
import csv
csvFile = open("instance.csv", "r")
dict_reader = csv.DictReader(csvFile)
# 输出第一行,也就是数据名称那一行
print(dict_reader.fieldnames) # >>> ['name', 'score']
很好理解,fieldnames 是dict_reader的一个属性,表示CSV文档的数据名称。
如果觉得”DictReader”对象不方便对数据处理,还想转换成我们上边那种普通的Python字典对象,也很容易:3行代码即可解决问题
result = {}
for item in dict_reader:
result[item["name"]] = item["score"]
print(result) # >>> {'Wang': '80', 'Li': '90', 'Zhang': '100'}
4.写入字典(dict)数据
使用 csv.DictWriter 对象
import csv
with open(r'e:\zarten.csv', 'w', newline='') as csvfile:
fieldnames = ['name', 'age']
csv_writer = csv.DictWriter(csvfile, fieldnames= fieldnames, delimiter=' ')#csv中默认,分隔单元格,delimiter可以不指定
csv_writer.writeheader()
csv_writer.writerow({'name' : 'Zarten1', 'age' : 1})
csv_writer.writerow({'name' : 'Zarten2', 'age' : 2})
csv_writer.close()
5. DictWriter 以字典形式写入
DictReader可以用来把CSV文件以字典的形式读入,当然还有相对的DictWriter以字典的形式写入内容,比如:
import csv
csvFile = open("instance.csv", "w")
# 文件头以列表的形式传入函数,列表的每个元素表示每一列的标识
fileheader = ["name", "score"]
dict_writer = csv.DictWriter(csvFile, fileheader)
# 但是如果此时直接写入内容,会导致没有数据名,所以,应先写数据名(也就是我们上面定义的文件头)。
# 写数据名,可以自己写如下代码完成:
dict_writer.writerow(dict(zip(fileheader, fileheader)))
# 之后,按照(属性:数据)的形式,将字典写入CSV文档即可
dict_writer.writerow({"name": "Li", "score": "80"})
csvFile.close()
不过,csv也提供了专门的函数 writeheader()来实现添加文件头(数据名),简化开发者的工作,只需要将下面的代码:
dict_writer.writerow(dict(zip(fileheader, fileheader)))
改成这种形式:
dict_writer.writeheader()
上面的两个函数是一样的。之所以这个函数没有任何参数,实际上,是因为在建立对象dict_writer时,已经设定了参数
写入完成。之后,该怎么读,还是怎么读:
import csv
with open("instance.csv", "r") as csvFile:
dict_reader = csv.DictReader(csvFile)
for i in dict_reader:
print(i) # >>> {'name': 'Li', 'score': '80'}
csv读取
1.读取普通csv
使用 csv.reader 对象
import csv
with open(r'e:\zarten.csv', 'r', newline='') as csvfile:
csv_reader = csv.reader(csvfile, delimiter= ' ')
headers = next(csv_reader) #获取第一行,可能是头
print(headers)
for row in csv_reader:
print(row)
#输出结果:
# ['name', 'age']
# ['Zarten1', '1']
# ['Zarten2', '2']
2.读取字典(dict)csv
使用 csv.DictReader 对象
import csv
with open(r'e:\zarten.csv', 'r', newline='') as csvfile:
csv_reader = csv.DictReader(csvfile, delimiter= ' ')
for row in csv_reader:
print(row['name'], row['age'])
简单的实例:
#coding=utf8
import csv
import os
import configparser
import pdb
# import glob
# file_pathes = glob.glob('./*')
# for file_path in file_pathes:
# print(file_path)
# pdb.set_trace()
# os.walk()
def get_config(array_item_name = "demo_folder",array_name = "path", config_filename = "configs.ini"):
conf = configparser.SafeConfigParser()
conf.read(config_filename)
return conf.get(array_name, array_item_name)
def read_csv(csv_file = None, from_row = 8, to_row = None):
output = []
if csv_file is not None and os.path.isfile(csv_file):
# 读取csv至字典
csvFile = open(csv_file, "r")
reader = csv.reader(csvFile)
# 建立空字典
for row in reader:
if reader.line_num < from_row: continue
if to_row is int and to_row >= from_row and reader.line_num > to_row: continue
output.append(row)
csvFile.close()
return output
def get_csv_header(csv_file = None, from_row = 0, to_row = 8):
output = []
if csv_file is not None and os.path.isfile(csv_file):
output = read_csv(csv_file, from_row, to_row)
return output
def write_csv(csv_new_file, csv_data):
with open(csv_new_file, "w") as f:
writer = csv.writer(f)
writer.writerows(csv_data)
f.close()
def __main__():
daily_transaction_folder = get_config('daily_transaction_folder')
daily_csv_files = []
for index, filename in enumerate(os.listdir(daily_transaction_folder)):
# print(str(index)+": "+filename)
if filename.endswith("Transaction.csv"):
full_path_file = os.path.join(daily_transaction_folder, filename)
csv_file_data = read_csv(full_path_file)
daily_csv_files += csv_file_data
# write_csv(filename, read_csv(full_path_file))
# print(read_csv(full_path_file))
# exit(0)
# daily_csv_files.append(full_path_file)
# daily_csv_files.append(read_csv(full_path_file))
# print(read_csv(full_path_file))
# exit(0)
# print(full_path_file)
write_csv("demo.csv", daily_csv_files)
__main__()
pip3 install openpyxl
excel写入
import openpyxl
file_path = r'e:\zarten.xlsx'
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'Zarten_info'
headers = ['name', "age"]
sheet.cell(1, 1, value=headers[0])
sheet.cell(1, 2 ,value=headers[1])
rows1 = ['Zarten1', 1]
sheet.append(rows1)
rows2 = ['Zarten2', 2]
sheet.append(rows2)
excel读取
import openpyxl
file_path = r'e:\zarten.xlsx'
wb = openpyxl.load_workbook(file_path)
sheet = wb['Zarten_info']
for row in sheet.rows:
row_info = [row[0].value, row[1].value]
print(row_info)
for cell in row:
print(cell.value)
本文:Python读写csv文件, Python 读取指定csv行, Python生成csv文件, Python操作csv文件
![]()
Related Posts

python: try catch, Python 异常处理, Python 获取异常名称, try与except处理异常语句

Python 3 之 Requests快速上手: Python爬虫利器Requests库的用法, Requests库简明使用教程