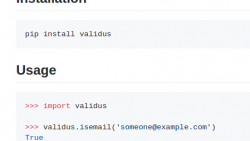
Validus A dead simple Python data validation library.…
July 13, 2020
Python 合并/追加excel, Python 合并/追加 csv, Merging Spreadsheets with Python–Append
将多个电子表格合并在一起是一项常见的任务。可以通过两种方式进行合并:
- 追加 -电子表格彼此并置

Python 合并/追加excel, Python 合并/追加 csv, Merging Spreadsheets with Python–Append - 合并 -根据所选列的相同值水平合并电子表格列

Python 合并/追加excel, Python 合并/追加 csv, Merging Spreadsheets with Python–Append
档案
本教程将使用三个文件。您可以通过单击以下链接下载它们:MarketingAnalystNames.xlsx,SalesRepNames.xlsx,SeniorLeadershipNames.xlsx
完整代码
这是追加三个文件的完整代码
# pip install pandas
# pip install xlrd
import pandas as pd
#将所有三个文件读入pandas数据帧
marketing_analyst_names = pd.read_excel("MarketingAnalystNames.xlsx")
sales_rep_names = pd.read_excel("SalesRepNames.xlsx")
senior_leadership_names = pd.read_excel("SeniorLeadershipNames.xlsx")
#创建文件列表,以便您希望它们被附加
all_df_list = [marketing_analyst_names, sales_rep_names, senior_leadership_names]
#合并all_df_list中的所有数据框
#pandas将基于相似的列名自动追加
appended_df = pd.concat(all_df_list)
#将附加的数据框写入Excel文件
#添加index = False参数不包括行号
appended_df.to_excel("AllCompanyNames.xlsx", index=False)
1. 读取所有三个电子表格
在与三个电子表格相同的文件夹中创建一个python文件,并将其命名为append.py
首先,我们将导入我们的pandas库,并将其缩写为pd。该PD的缩写是惯例,技术上你可以使用进口大熊猫因为是和取代一切PD与代码pandas
import pandas as pd
我们将在没有任何额外参数的情况下阅读第一张表,因为我们只有文本数据,第一行是列名,因此我们可以使用pandas read_excel命令读取所有三个文件,而无需任何参数
marketing_analyst_names = pd.read_excel("MarketingAnalystNames.xlsx")
sales_rep_names = pd.read_excel("SalesRepNames.xlsx")
senior_leadership_names = pd.read_excel("SeniorLeadershipNames.xlsx")
现在,我们有三个变量,它们包含熊猫数据帧,这些数据帧以行和列的格式包含了excel文件中的所有值
2. 合并所有三个数据框
现在我们要合并所有三个数据帧
- 我们将创建一个包含所有三个数据帧的列表。该列表中数据帧的顺序将确定文件的附加方式
all_df_list = [marketing_analyst_names,sales_rep_names,senior_leadership_names]
- 2.附加所有三个数据帧的命令是1行功能。我们将使用列表调用pd.concat函数,该函数将按此顺序附加所有数据帧,并将附加的数据帧分配给变量appended_df
appended_df = pd.concat(all_df_list)
通过匹配相似的列名来完成追加。如果列名不同,则附加项不会将值堆叠在一起。
我鼓励大家使用不同的列名创建虚拟电子表格,以了解附加内容受到的影响
3. 写入Excel文件
现在我们有了附加的数据框,我们可以将其写入Excel文件。我们使用附加数据帧上的to_excel函数执行此操作。我们还将添加参数index = False,它不会输出任何行号。(试玩一下参数,看看哪个对您有意义)
appended_df.to_excel("AllCompanyNames.xlsx", index=False)
现在我们已经完成了代码,我们需要打开终端并转到保存了所有三个文件和append.py文件的文件夹
我们将从终端运行此脚本
$ python append.py
瞧!现在,我们应该在与三个电子表格相同的文件夹中有一个名为AllCompanyNames.xlsx的文件,并且我们的Python脚本包含附加的所有三个文件!
合并两个CSV 文件 How to: Combine two CSV files into one file
import csv
reader = csv.reader(open("sample.csv"))
reader1 = csv.reader(open("sample1.csv"))
f = open("combined.csv", "w")
writer = csv.writer(f)
for row in reader:
writer.writerow(row)
for row in reader1:
writer.writerow(row)
f.close()
OUTPUT combined.csv a,1 b,2 c,3 d,4 INPUT FILES sample1.csv sample.csv
或者:
使用Python合并多个CSV(相同)文件的步骤
注意:我们假设-所有文件在内部具有相同的列数和相同的信息
步骤1:导入模块并设置工作目录
首先,我们将从加载程序所需的模块并选择工作文件夹开始:
import os, glob import pandas as pd path = "/home/user/data/"
步骤2:按格式匹配CSV文件
下一步是收集所有需要合并的文件。这将通过以下方式完成:
all_files = glob.glob(os.path.join(path, "data_*.csv"))
下一个代码:data_*.csv仅匹配文件:
- 从…开始
data_ - 带有文件扩展名
.csv
考虑到使用了正则表达式匹配,您可以根据需要自定义选择。
第3步:合并列表中的所有文件并导出为CSV
最后一步是将所有选定文件加载到单个DataFrame中,并在需要时将其转换回csv:
all_csv = (pd.read_csv(f, sep=',') for f in all_files) df_merged = pd.concat(all_csv, ignore_index=True) df_merged.to_csv(path+"merged.csv")
请注意,您可以通过以下方式更改分隔符:sep=','或更改要加载的标题和行
您可以在此处找到有关将DataFrame转换为CSV文件的更多信息:pandas.DataFrame.to_csv
完整代码
在下面,您可以找到可用于合并多个CSV文件的完整代码。
import os, glob import pandas as pd path = "samples/" #path = "/home/user/data" all_files = glob.glob(os.path.join(path, "data_*.csv")) all_csv = (pd.read_csv(f, sep=',') for f in all_files) df_merged = pd.concat(all_csv, ignore_index=True) df_merged.to_csv(path + "merged.csv", index=False, encoding='utf8')

通过跟踪将多个CSV(相同)文件与Python合并的步骤
现在,让我们说您想将多个CSV文件合并到一个DataFrame中,还希望有一列代表该行来自哪个文件。就像是:
| ROW | COL | COL2 | FILE |
|---|---|---|---|
| 1 | A | B | data_201901.csv |
| 2 | C | D | data_201902.csv |
只需对上面的代码进行少量更改即可非常轻松地实现:
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "*.csv"))
all_df = []
for f in all_files:
df = pd.read_csv(f, sep=',')
df['file'] = f.split('/')[-1]
all_df.append(df)
merged_df = pd.concat(all_df, ignore_index=True, sort=True)
在此示例中,我们遍历所有选定文件,然后提取文件名并创建一个包含此名称的列。
列不同时合并多个CSV文件
有时,某些列的CSV文件会有所不同,或者只是顺序错误,它们可能是相同的。在此示例中,您可以找到如何在没有相同结构的情况下合并CSV文件:
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "*.csv"))
all_df = []
for f in all_files:
df = pd.read_csv(f, sep=',')
f['file'] = f.split('/')[-1]
all_df.append(df)
merged_df = pd.concat(all_df, ignore_index=True, , sort=True)
pandas将通过以下方法对齐数据:pd.concat。如果缺少列,则给定CSV文件的行将包含NaN值:
| ROW | COL | COL2 | COL_201901 | FILE |
|---|---|---|---|---|
| 1 | A | B | AA | data_201901.csv |
| 2 | C | D | NaN | data_201902.csv |
如果需要比较两个csv文件与Python和Pandas的区别,则可以检查:Python Pandas根据列比较两个CSV文件
有关pandas concat的更多信息:pandas.concat
奖励:使用Windows / Linux合并多个文件
有时,足以使用来自操作系统的本地工具,或者在文件很大的情况下。使用python串联多个巨大文件可能具有挑战性。在这种情况下,对于Linux,可以使用:
sed 1d data_*.csv > merged.csv
在这种情况下,我们通过匹配以开头的所有文件来处理当前文件夹data_。这很重要,因为如果您尝试执行以下操作:
sed 1d *.csv > merged.csv
您还将尝试合并新的输出文件,这可能会导致问题。另一个重要的注意事项是,这将跳过每个文件的第一行或标题。为了包含标题,您可以执行以下操作:
sed -n 1p data_1.csv > merged.csv sed 1d data_*.csv >> merged.csv
与之等效的Windows将是:
C:\> copy data_*.csv merged.csv
要么
type data_*.csv > merged.csv
本文:Python 合并/追加excel, Python 合并/追加 csv, Merging Spreadsheets with Python–Append
![]()
Related Posts

Python导入模块的几种姿势, Python导入的路径, 绝对导入, 相对导入, 模块加载和路径查找, python import 路径
python中shutil文件操作模块, shutil用法, shutil代码示例, shutil 高阶文件操作, shutil库详解, python文件操作库
