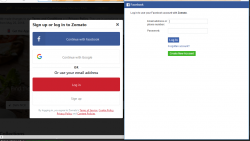
许多网站使用社交媒体登录来简化用户的登录过程。在大多数情况下,如果单击该按钮,则会打开一个新的弹出窗口,用户必须在其中输入用户凭据。可以手动在浏览器中切换窗口并输入所需的凭据以登录。但是,如果使用webdriver进行无人值守的Web访问,则驱动程序不能仅自动切换窗口。我们需要更改驱动程序中的窗口句柄,以便在弹出窗口中输入登录凭据。Selenium具有使用同一驱动程序切换窗口以访问多个窗口的功能。 首先,我们必须从Webdriver获取当前的窗口句柄,这可以通过以下方式完成: driver.current_window_handle 我们需要保存它以获取当前的窗口句柄。弹出窗口出现后,我们必须立即获取所有可用窗口句柄的列表。 driver.window_handles …
January 6, 2020
Python Selenium 的 XPath 定位方式详解, Selenium Webdriver中使用XPath Contains、Sibling函数定位

先介绍一下 XPath。XPath 是一门在 XML 文档中查找信息的语言。可用来在 XML 文档中对元素和属性进行遍历。
在 selenium 中定位元素,使用 XPath 能更好的抽象代码(比如讲 XPath 表达式提取成一个单独的配置)。所以我在日常使用中尽量使用 XPath。
HTML与XML
html 是标记语言,XML 是标记语言的元语言。
HTML和XML的最大区别在于:HTML是一个定型的标记语言,它用固有的标记来描述,显示网页内容。比如<H1>表示首行标题,有固定的尺寸。相对的,XML则没有固定的标记,XML不能描述网页具体的外观,内容,它只是描述内容的数据形式和结构。
Xpath定位方法
绝对定位
driver.findElement(By.xpath("/html/body/div/form/input"))
特点:这个路径是从网页起始标签开始一直到要定位的元素的路径,如果要定位的元素在页面最下面,则这个Xpath路径会非常长。如果在要定位的元素与页面开始之间的元素有任何增减,元素定位就会失败。
相对定位
driver.findElement(By.xpath("//input") )
返回查找到的第一个符合条件的元素。
特点:相对路径一般只会包含与被定位元素最近的几层元素有关,相对路径写的好的话,页面变动影响最小,而且定位准确。
索引定位
使用索引定位元素,索引的初始值为1。
driver.findElement(By.xpath("//input[2]") )
返回查找到的第二个符合条件的元素。
属性值定位
driver.findElement(By.xpath("//input[@id='username']"));
driver.findElement(By.xpath("//img[@alt='flowr']"));
特点:属性定位也是比较常用的方法,如果元素中没有常见的id,name,class等直接有方法可调用的属性,也可以查找元素中是否有其他能唯一标识元素的属性,如果有,就可以用此方法定位。
逻辑运算符 and与or
driver.findElement(By.xpath("//input[@id='username' and @name='userID']"));
特点:多个属性值联合定位,更能准确定位到元素。并且如果多个相同标签的元素,如果其包含的属性值有不同的,也可以用这个方法区分开来。
属性名定位
driver.findElement(By.xpath("//input[@button]"))
特点:此方法可以区分同一种标签,含有不同属性名的元素。定位相对简单一些儿,但也同样存在着无法区分同种标签含有同种属性名的多个元素,这个时候要配合索引定位才行。
属性值匹配
(a)starts-with()
driver. findElement(By.xpath ("//input[stars-with(@id,'user')]"))
(b)ends-with()
driver. findElement(By.xpath ("//input[ends-with(@id,'name')]"))
(c)contains()
driver. findElement(By.xpath ("//input[contains(@id,"ernam")]"))
特点:此方法更加灵活,可以定位属性值不太规律,或是部分变动,中间有空格的情况。注:如果属性值中间包含空格,Webdriver定位的时候容易出错,时而能定位到时而定位不到,所以应该避免用含用空格的属性值定位。可以采用此方法,进行部分属性值定位。
任意属性值匹配
driver.findElement(By.xpath("//input[@*='username']"))
特点:此方法相当于模糊查询,只要欲定位的标签,如input中任何属性值等于‘username’,就能匹配成功。缺点,可能会匹配含有这个属性值的其他元素,所以我们在定位的时候要查看一下这个元素值在页面中是否唯一。
XPath Contains、Sibling函数定位
在一般情况下,我们通过简单的xpath即可定位到目标元素,但对于一些既没id又没name,而且其他属性都是动态的情况就很难通过简单的方式进行定位了。
在这种情况下,我们需要使用xpath1.0内置的函数来进行定位,下面我们重点讨论一下3个函数:
- Contains
- Sibling
Contains函数
通过contains函数,我们可以提取匹配特定文本的所有元素。

例如在百度首页,我们使用contains定位包含“新闻”文本的元素。
"//div/a[contains(text(), 新闻)]"
在python selenium中使用xpath contains定位,代码片段如下:
driver.find_element_by_xpath("//div/a[contains(text(), 新闻)]")
sibling函数
通过sibling函数我们可以提取指定元素的所有同级元素,即获取目标元素的所有兄弟节点。
例如通过刚才“新闻”节点来定位“hao123”节点。
"//div/following-sibling::a[contains(text(), 新闻)]"
python selenium代码片段为如下
driver.find_element_by_xpath( u"//div/a[contains(text(), '%s')]/following-sibling::*" % u"新闻")
通过刚才“新闻”节点来定位其所有的兄弟节点。
python selenium代码片段如下(注意这里用的是find_elements_by_xpath):
driver.find_elements_by_xpath( u"//div/a[contains(text(), '%s')]/following-sibling::*" % u"新闻")
下面我们看一个完整的代码示例:
#_*_ coding:utf-8 _*_
__author__ = '苦叶子'
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
if __name__ == '__main__':
driver = webdriver.Ie()
driver.get(u"http://www.baidu.com")
# 定位 通过contains 定位包含“新闻”的元素
new_node = driver.find_element_by_xpath(
u"//div/a[contains(text(), '%s')]" % u"新闻")
print new_node.text
# 定位 “新闻”元素的兄弟节点“hao123”
hao123_node = driver.find_element_by_xpath(
u"//div/a[contains(text(), '%s')]/following-sibling::*" % u"新闻")
print hao123_node.text
# 定位 “新闻”元素的所有兄弟节点
all_node = driver.find_elements_by_xpath(
u"//div/a[contains(text(), '%s')]/following-sibling::*" % u"新闻")
for ee in all_node:
print ee.text
driver.quit()
根据部分元素属性定位
driver.find_element_by_xpath("//div[contains(@id, 'btn-attention')]")
driver.find_element_by_xpath("//div[starts-with(@id, 'btn-attention')]")
driver.find_element_by_xpath("//div[ends-with(@id, 'btn-attention')]") # 这个需要结尾是‘btn-attention’
contains(a, b) 如果a中含有字符串b,则返回true,否则返回false
starts-with(a, b) 如果a是以字符串b开头,返回true,否则返回false
ends-with(a, b) 如果a是以字符串b结尾,返回true,否则返回false
这里要多嘴一句,各种浏览器对xpath的支持情况不一样,像IE就差点,所以有时候会出现xpath在一个浏览器能定位到但在另一个浏览器定位不到的问题,不要惊讶。。
附上一个此类型问题:
Xpath “ends-with” does not work
XPath 轴匹配
普通方式
# -*- coding: utf-8 -*-
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
# 1.xpath 父子关系
print driver.find_element_by_xpath("//div[@id='B']/div").text
# 1.xpath 父子关系
# `.`代表当前节点; '..'代表父节点
print driver.find_element_by_xpath("//div[@id='C']/../..").text
# 1.xpath,通过父节点获取其哥哥节点
print driver.find_element_by_xpath("//div[@id='D']/../div[1]").text
# 1.xpath,通过父节点获取其弟弟节点
print driver.find_element_by_xpath("//div[@id='D']/../div[3]").text
XPath 轴
# 1.xpath轴 child 父子关系
print driver.find_element_by_xpath("//div[@id='B']/child::div").text # child是xpath默认的轴,可以忽略不写
# 1.xpath轴 parent 父子关系
print driver.find_element_by_xpath("//div[@id='C']/parent::*/parent::div").text
# 1.xpath轴 preceding-sibling 哥哥节点
print driver.find_element_by_xpath("//div[@id='D']/preceding-sibling::div[1]").text
# 1.xpath轴 following-sibling 弟弟节点
print driver.find_element_by_xpath("//div[@id='D']/following-sibling::div[1]").text
# 1.xpath轴 following 弟弟节点
print driver.find_element_by_xpath("//div[@id='D']/following::*").text
xpath常用函数
- child 选取当前节点的所有子节点
- parent 选取当前节点的父节点
- descendant 选取当前节点的所有后代节点
- ancestor 选取当前节点的所有先辈节点
- descendant-or-self 选取当前节点的所有后代节点及当前节点本身
- ancestor-or-self 选取当前节点所有先辈节点及当前节点本身
- preceding-sibling 选取当前节点之前的所有同级节点
- following-sibling 选取当前节点之后的所有同级节点
- preceding 选取当前节点的开始标签之前的所有节点
- following 选去当前节点的开始标签之后的所有节点
- self 选取当前节点
- attribute 选取当前节点的所有属性
- namespace 选取当前节点的所有命名空间节点
路径表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 匹配任意多的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
通配符
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 | |
|---|---|---|
| * | 匹配任何元素节点。 | |
| @* | 匹配任何属性节点。 | |
| node() | 匹配任何类型的节点。 | 、 |
例子:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
多个表达式
通过在路径表达式中使用“|”运算符,您可以选取若干个路径 例子:
| 路径表达式 | 结果 | |
|---|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
关键字
| 关键字 | 结果 |
|---|---|
| starts-with | 顾名思义,匹配一个属性开始位置的关键字 |
| contains | 匹配一个属性值中包含的字符串 |
| text() | 匹配的是显示文本信息,此处也可以用来做定位用 |
| Sibling | 提取指定元素的所有同级元素,即获取目标元素的所有兄弟节点。 |
例子:
| 例子 | 结果 |
|---|---|
| //input[starts-with(@name,’name1’)] | 查找name属性中开始位置包含’name1’关键字的页面元素 |
| //input[contains(@name,’na’)] | 查找name属性中包含na关键字的页面元素 |
| //a[text()=’百度搜索’] | |
| //a[contains(text(),”百度搜索”)] | |
| //a[not(contains(@id, ‘xx’))] | |
| //div[(contains(@class,’typeA’) or contains(@class,’typeB’)) and not(contains(@class,’ng-hide’))] |
参考资料
本文:Python Selenium 的 XPath 定位方式详解, Selenium Webdriver中使用XPath Contains、Sibling函数定位
![]()
Related Posts

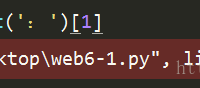
python 3.5: a bytes-like object is required,not ‘str’ 报错
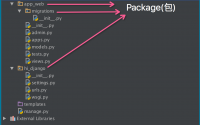
Python导入模块的几种姿势, Python导入的路径, 绝对导入, 相对导入, 模块加载和路径查找, python import 路径
