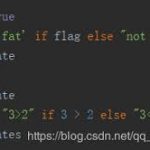
December 27, 2018
Python 网络爬虫:Python解析html, Beautiful Soup的用法

我们还有一个更强大的工具,叫Beautiful Soup,有了它我们可以很方便地提取出HTML或XML标签中的内容,实在是方便,这一节就让我们一起来感受一下Beautiful Soup的强大吧。
1. Beautiful Soup的简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicod… Read More