让MySQL搜索区分大小写或排序时分大小写方法如下: 1.在SQL中强制 SELECT `field` FROM `table` WHERE BINARY…
January 7, 2016
MongoDB 教程五: MongoDB固定集合和性能优化 (索引Indexes, 优化器, 慢查询profile)
MongoDB 系列教程索引 : MongoDB 教程索引 (附有视频)
mongodb索引详解(Indexes)
索引介绍
索引在mongodb中被支持,如果没有索引,mongodb必须扫描每一个文档集合选择匹配的查询记录。这样扫描集合效率并不高,因为它需要mongod进程使用大量的数据作遍历操作。
索引是一种特殊的数据结构,它保存了小部分简单的集合数据。索引存储了一些特殊字段,并将其排序。
从根本上讲,索引在mongodb中和其他数据库系统是类似的。mongodb规定了索引的集合级别、支持索引任何字段或者子字段在mongodb文档集合中。
索引优化查询方案
要考虑数据之间的关系,做查询优化。
创建索引支持常见的面向用户的查询,确保扫描读取文件最小数量。
索引可以优化特定场景中的其它业务的性能。
排序返回数据
来看看一个索引的具体例子(其实就相当于我们查询字段一样的)
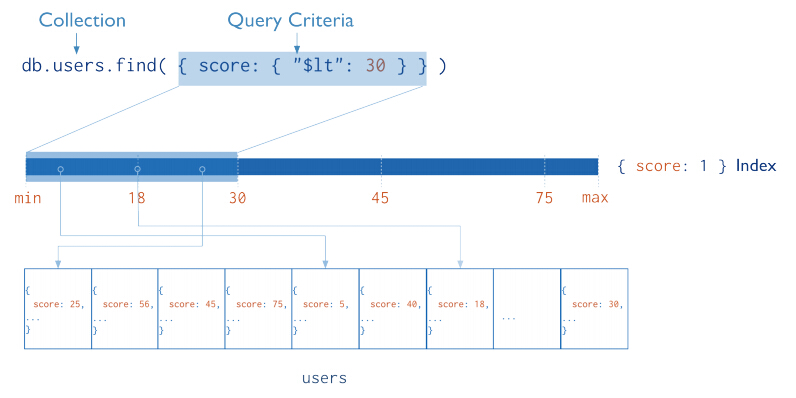
上图展示了有索引和无索引的查询方式,目测都可以看出效率。
大数据查询
当我们使用索引的时候,查询时候根据对应字段在索引中查询,无需将数据加载到内存中,直接扫描索引拿数据。这些大数据查询是非常有效率的。
索引类型
MongoDB提供了一些不同的索引类型支持的数据和查询的具体类型
- Default _id (默认_id索引)所有mongodb默认都有一个_id字段索引,如果我们不指定_id的值会自动生成一个ObjectId值。
该_id索引是唯一的,并且可以防止客户端对_id字段值相同插入两个。# 查询articles集合的索引 db.articles.getIndexes(); # 添加titlei字段索引,并且为升序 db.articles.ensureIndex({title:1}); #重构索引(慎用) db.articles.reIndex();注意:索引排序规则升序:1,降序-1 - Single Field (单字段索引)mongodb允许定义单个字段的索引,与default _id一样,只是字段不同。
- Compound Index (复合索引[多字段索引])mongodb中可以自定多个字段的索引。例如,如果一个复合指标包括
{userid:1,score:-1 },索引排序第一的用户名后,在每一个用户标识符值,按得分++倒序++排序。{ "_id": ObjectId(...), "item": "Banana", "category": ["food", "produce", "grocery"], "location": "4th Street Store", "stock": 4, "type": "cases", "arrival": Date(...) }创建方法:
# 创建item、stock字段的复合索引,并且升序排序 db.products.ensureIndex( { "item": 1, "stock": 1 } )注意:Hashed 字段不能创建索引,如果创建将出现错误Application Sort Order 使用案例:降序用户名升序时间。
# 查询结果集中排序 db.events.find().sort( { username: -1, date: 1 } ) # 查询结果集中排序 db.user_scores.find().sort({score:-1,date:-1}).limit(1) # 执行相关查询可以看出查询效率大大提高 - MultiKey Index (多键索引)官方文档中给出这样一个案例:
{ userid:"marker", address:[ {zip:"618255"}, {zip:"618254"} ] } # 创建索引,并将zip升序排列 db.users.ensureIndex({"address.zip": 1}); # 假如我们做这样的查询 db.users.find({"addr":{"$in":[{zip:"618254"}]}})注意:你可以创建 多键复合索引(multikey compound indexes) - Geospatial Index (地理空间索引)
db.places.ensureIndex( { loc : "2dsphere" } ) - Text Indexes (文本索引)文本索引是在2.4版本更新的,提供了文本搜索文档中的集合功能,文本索引包含:字符串、字符数组。使用
$text做查询操作。2.6版本 默认情况下使文本搜索功能。在MongoDB 2.4,你需要使文本搜索功能手动创建全文索引和执行文本搜索# 创建文本索引 (2.6你就不用这么麻烦了哦) db.articles.ensureIndex({content:"text"});复合索引可以包含文本索引 称为:复合文本索引(compound text indexes),但有限制
1. 复合文本索引不能包含任何其他特殊索引类型,比如:多键索引(multi-key Indexes) 2. 如果复合文本索引包含文本索引的键,执行$text查询必须相同查询条件。可能翻译不对原文: (If the compound text index includes keys preceding the text index key, to perform a $text search, the query predicate must include equality match conditions on the preceding keys1) - Hashed Indexes (哈希码索引)哈希索引在2.4版本更新的,将实体的的哈希值作为索引字段,
# 给user_scores的score字段创建一个哈希索引 db.user_scores.ensureIndex( { score: "hashed" } )
索引的属性
除了众多索引类型的支持以外,还可以使用各种属性来调整性能。
- TTL Indexes
它是一个特殊的索引,可以在某个时间自动的删除文档集合的索引。对于一些信息数据比如说日志、事件对象、会话信息,只需要存放在数据库一个特定期限。使用限制:1. 不支持复合索引 2. 必须是date时间类型字段 3. 如果是date数组,按照最早时间过期。
TTL index不保证过期时间立即删除,
后台任务没60秒运行删除,
依赖于mongod进程 - Unique Indexes
# 创建唯一索引 db.members.ensureIndex( { "user_id": 1 }, { unique: true } )注意:如果字段为null,那么就以null值,但不能重复插入空值。如果collection中有两个实体唯一索引字段为空,则不能创建唯一索引也就是说,我们还可以利用它作为类似于关系型数据库的唯一约束。
# 强制插入空值对象后报错 > db.users.insert({content:"unique testing"}) WriteResult({ "nInserted" : 0, "writeError" : { "code" : 11000, "errmsg" : "insertDocument :: caused by :: 11000 E11000 duplicat e key error index: test.users.$dsadsadsa dup key: { : null }" } }) - Sparse Indexes
db.addresses.ensureIndex( { "xmpp_id": 1 }, { sparse: true } ) - background属性 高效修改/创建索引在项目运行中,如果我们直接采用前面的方法创建索引或者修改索引,那么数据库会阻塞建立索引期间的所有请求。mongodb提供了background属性做后台处理。
db.addresses.ensureIndex( { "xmpp_id": 1 }, {background: true } )我们知道如果哦阻塞所有请求,建立索引就会很快,但是使用系统的用户就需要等待,影响了数据库的操作,因此可以更具具体情况来选择使用background属性
索引名称
# 自动生成索引名称
db.products.ensureIndex( { item: 1, quantity: -1 } )
# 被命名为: item_1_quantity_-1
# 自定义索引名称
db.products.ensureIndex( { item: 1, quantity: -1 } , { name: "inventory" } )
索引交叉
在2.6版本中更新的,这块没有深入了解。
管理索引
# 添加/修改索引
db.users.ensureIndex({name:"text"});
# 删除集合所有索引
db.users.dropIndexes();
# 删除特定索引 (删除id字段升序的索引)
db.users.dropIndex({"id":1})
# 获取集合索引
db.users.getIndexes();
# 重构索引
db.users.reIndex();
总结
索引分类:
- Default _id (默认_id索引)
- Single Field (单字段索引)
- Compound Index (复合索引[多字段索引])
- MultiKey Index (多键索引)
- Geospatial Index (地理空间索引)
- Text Indexes (文本索引)
- Hashed Indexes (哈希码索引)
为什么要使用索引?想想查字典原理就明白了。
MongoDB 查询优化分析
摘要:
在MySQL中,慢查询日志是经常作为我们优化查询的依据,那在MongoDB中是否有类似的功能呢?答案是肯定的,那就是开启Profiling功能。该工具在运行的实例上收集有关MongoDB的写操作,游标,数据库命令等,可以在数据库级别开启该工具,也可以在实例级别开启。该工具会把收集到的所有都写入到system.profile集合中,该集合是一个capped collection。更多的信息见:http://docs.mongodb.org/manual/tutorial/manage-the-database-profiler/
使用说明:
1:Profiling级别说明
0:关闭,不收集任何数据。 1:收集慢查询数据,默认是100毫秒。 2:收集所有数据
2:开启Profiling和设置
1:通过mongo shell:
#查看状态:级别和时间
drug:PRIMARY> db.getProfilingStatus()
{ "was" : 1, "slowms" : 100 }
#查看级别
drug:PRIMARY> db.getProfilingLevel()
1
#设置级别
drug:PRIMARY> db.setProfilingLevel(2)
{ "was" : 1, "slowms" : 100, "ok" : 1 }
#设置级别和时间
drug:PRIMARY> db.setProfilingLevel(1,200)
{ "was" : 2, "slowms" : 100, "ok" : 1 }
以上要操作要是在test集合下面的话,只对该集合里的操作有效,要是需要对整个实例有效,则需要在所有的集合下设置或则在开启的时候开启参数:
2:不通过mongo shell:
mongod --profile=1 --slowms=15 #或则在配置文件里添加2行: profile = 1 slowms = 300
3:关闭Profiling
# 关闭
drug:PRIMARY> db.setProfilingLevel(0)
{ "was" : 1, "slowms" : 200, "ok" : 1 }
4:修改“慢查询日志”的大小
#关闭Profiling
drug:PRIMARY> db.setProfilingLevel(0)
{ "was" : 0, "slowms" : 200, "ok" : 1 }
#删除system.profile集合
drug:PRIMARY> db.system.profile.drop()
true
#创建一个新的system.profile集合
drug:PRIMARY> db.createCollection( "system.profile", { capped: true, size:4000000 } )
{ "ok" : 1 }
#重新开启Profiling
drug:PRIMARY> db.setProfilingLevel(1)
{ "was" : 0, "slowms" : 200, "ok" : 1 }
注意:要改变Secondary的system.profile的大小,你必须停止Secondary,运行它作为一个独立的,然后再执行上述步骤。完成后,重新启动加入副本集。
慢查询(system.profile)说明:
通过下面的例子说明,更多信息见:http://docs.mongodb.org/manual/reference/database-profiler/
1:参数含义
drug:PRIMARY> db.system.profile.find().pretty()
{
"op" : "query", #操作类型,有insert、query、update、remove、getmore、command
"ns" : "mc.user", #操作的集合
"query" : { #查询语句
"mp_id" : 5,
"is_fans" : 1,
"latestTime" : {
"$ne" : 0
},
"latestMsgId" : {
"$gt" : 0
},
"$where" : "new Date(this.latestNormalTime)>new Date(this.replyTime)"
},
"cursorid" : NumberLong("1475423943124458998"),
"ntoreturn" : 0, #返回的记录数。例如,profile命令将返回一个文档(一个结果文件),因此ntoreturn值将为1。limit(5)命令将返回五个文件,因此ntoreturn值是5。如果ntoreturn值为0,则该命令没有指定一些文件返回,因为会是这样一个简单的find()命令没有指定的限制。
"ntoskip" : 0, #skip()方法指定的跳跃数
"nscanned" : 304, #扫描数量
"keyUpdates" : 0, #索引更新的数量,改变一个索引键带有一个小的性能开销,因为数据库必须删除旧的key,并插入一个新的key到B-树索引
"numYield" : 0, #该查询为其他查询让出锁的次数
"lockStats" : { #锁信息,R:全局读锁;W:全局写锁;r:特定数据库的读锁;w:特定数据库的写锁
"timeLockedMicros" : { #锁
"r" : NumberLong(19467),
"w" : NumberLong(0)
},
"timeAcquiringMicros" : { #锁等待
"r" : NumberLong(7),
"w" : NumberLong(9)
}
},
"nreturned" : 101, #返回的数量
"responseLength" : 74659, #响应字节长度
"millis" : 19, #消耗的时间(毫秒)
"ts" : ISODate("2014-02-25T02:13:54.899Z"), #语句执行的时间
"client" : "127.0.0.1", #链接ip或则主机
"allUsers" : [ ],
"user" : "" #用户
}
除上面外还有:
scanAndOrder: scanAndOrder是一个布尔值,是True当一个查询不能使用的文件的顺序在索引中的排序返回结果:MongoDB中必须将其接收到的文件从一个游标后的文件进行排序。 如果scanAndOrder是False,MongoDB的可使用这些文件的顺序索引返回排序的结果。即:True:文档进行排序,False:使用索引。 moved 更新操作在磁盘上移动一个或多个文件到新的位置。表明本次update是否移动了硬盘上的数据,如果新记录比原记录短,通常不会移动当前记录,如果新记录比原记录长,那么可能会移动记录到其它位置,这时候会导致相关索引的更新.磁盘操作更多,加上索引 更新,会使得这样的操作比较慢. nmoved: 文件在磁盘上操作。 nupdated: 更新文档的数目
getmore是一个getmore 操作,getmore通常发生在结果集比较大的查询时,第一个query返回了部分结果,后续的结果是通过getmore来获取的。
如果nscanned(扫描的记录数)远大于nreturned(返回结果的记录数)的话,要考虑通过加索引来优化记录定位了。responseLength 如果过大,说明返回的结果集太大了,这时要看是否只需要必要的字段。
2:日常使用的查询
#返回最近的10条记录
db.system.profile.find().limit(10).sort({ ts : -1 }).pretty()
#返回所有的操作,除command类型的
db.system.profile.find( { op: { $ne : 'command' } } ).pretty()
#返回特定集合
db.system.profile.find( { ns : 'mydb.test' } ).pretty()
#返回大于5毫秒慢的操作
db.system.profile.find( { millis : { $gt : 5 } } ).pretty()
#从一个特定的时间范围内返回信息
db.system.profile.find(
{
ts : {
$gt : new ISODate("2012-12-09T03:00:00Z") ,
$lt : new ISODate("2012-12-09T03:40:00Z")
}
}
).pretty()
#特定时间,限制用户,按照消耗时间排序
db.system.profile.find(
{
ts : {
$gt : new ISODate("2011-07-12T03:00:00Z") ,
$lt : new ISODate("2011-07-12T03:40:00Z")
}
},
{ user : 0 }
).sort( { millis : -1 } )
总结:
Profiling 功能肯定是会影响效率的,但是不太严重,原因是他使用的是system.profile 来记录,而system.profile 是一个capped collection 这种collection 在操作上有一些限制和特点,但是效率更高,所以在使用的时候可以打开该功能,不需要一直打开。
来源:http://www.cnblogs.com/zhoujinyi/p/3566773.html
ts:时间戳
op: 操作类型
ns:执行操作的对象集合
millis:操作所花时间,毫秒
client: 执行操作的客户端
user: 执行操作的mongodb连接用户
mongostat详解
mongostat是mongdb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
它的输出有以下几列:
- inserts/s 每秒插入次数
- query/s 每秒查询次数
- update/s 每秒更新次数
- delete/s 每秒删除次数
- getmore/s 每秒执行getmore次数
- command/s 每秒的命令数,比以上插入、查找、更新、删除的综合还多,还统计了别的命令
- flushs/s 每秒执行fsync将数据写入硬盘的次数。
- mapped/s 所有的被mmap的数据量,单位是MB,
- vsize 虚拟内存使用量,单位MB
- res 物理内存使用量,单位MB
- faults/s 每秒访问失败数(只有Linux有),数据被交换出物理内存,放到swap。不要超过100,否则就是机器内存太小,造成频繁swap写入。此时要升级内存或者扩展
- locked % 被锁的时间百分比,尽量控制在50%以下吧
- idx miss % 索引不命中所占百分比。如果太高的话就要考虑索引是不是少了
- q t|r|w 当Mongodb接收到太多的命令而数据库被锁住无法执行完成,它会将命令加入队列。这一栏显示了总共、读、写3个队列的长度,都为0的话表示mongo毫无压力。高并发时,一般队列值会升高。
- conn 当前连接数
- time 时间戳
mongodb監控工具mongosniff
介绍
mongosniff提供了对数据库实时活动的低级别操作跟踪和嗅探视图。可以将mongosniff认为是专为MongoDB定制的,类似于tcpdump用于TCP/IP网络流量分析。mongosniff常用于驱动开发。
注意:mongosniff需要libpcap,并且只对类Unix系统可用。
相对于mongosniff,Wireshark,一个流行的网络嗅探工具,可用于侦测和解析MongoDB线协议。
用法
下面的命令连接到运行在localhost的27017和27018上的mongod或mongos:
mongosniff –source NET lo 27017 27018
下面的命令只记录运行在localhost的27018上的mongod或mongos的无效的BSON对象,用于驱动开发和问题跟踪:
mongosniff –objcheck –source NET lo 27018
实践
[root@test ~]# mongosniff –help
mongosniff: error while loading shared libraries: libpcap.so.0.9: cannot open shared object file: No such file or directory
[root@test ~]# which mongosniff
/usr/bin/mongosniff
[root@test ~]# ldd /usr/bin/mongosniff
linux-vdso.so.1 => (0x00007fffe2d7a000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x0000003558e00000)
librt.so.1 => /lib64/librt.so.1 (0x0000003559200000)
libpcap.so.0.9 => not found
libstdc++.so.6 => /usr/lib64/libstdc++.so.6 (0x0000003559e00000)
libm.so.6 => /lib64/libm.so.6 (0x0000003559600000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x000000355a600000)
libc.so.6 => /lib64/libc.so.6 (0x0000003558a00000)
/lib64/ld-linux-x86-64.so.2 (0x0000003558200000)
可以看出libpcap.so.0.9 => not found并没有找到。
[root@test ~]# cd /usr/lib64
[root@test lib64]# ls -al | grep libpcap
lrwxrwxrwx. 1 root root 16 Feb 26 17:28 libpcap.so.1 -> libpcap.so.1.4.0
-rwxr-xr-x 1 root root 260880 Nov 22 2013 libpcap.so.1.4.0
添加软连接。
[root@test lib64]# ln -s /usr/lib64/libpcap.so.1.4.0 /usr/lib64/libpcap.so.0.9
再次查看帮助。
[root@test lib64]# mongosniff –help
Usage: mongosniff [–help] [–forward host:port] [–source (NET <interface> | (FILE | DIAGLOG) <filename>)] [<port0> <port1> … ]
–forward Forward all parsed request messages to mongod instance at
specified host:port
–source Source of traffic to sniff, either a network interface or a
file containing previously captured packets in pcap format,
or a file containing output from mongod’s –diaglog option.
If no source is specified, mongosniff will attempt to sniff
from one of the machine’s network interfaces.
–objcheck Log hex representation of invalid BSON objects and nothing
else. Spurious messages about invalid objects may result
when there are dropped tcp packets.
<port0>… These parameters are used to filter sniffing. By default,
only port 27017 is sniffed.
–help Print this help message.
抓包:
[root@test lib64]# /usr/bin/mongosniff –source NET bond0 > /var/log/currentOp/sniff.log
下面是sniff.log中的部分内容:
10.10.0.1:55553 –>> 10.10.0.2:27017 MyTest.Pro 1042 bytes id:41d99 269721
query: { $query: { id: { $in: [ 380, 383 ] }, Availability.Status: { $lt: 5 }, $or: [ { id: { $lt: 331 } }, { id: { $gt: 200, $lt: 400 } }, { id: { $gt: 600, $lt: 800 } } ] }, $orderby: { Availability.Status: 1 } } ntoreturn: 0 ntoskip: 0 hasfields SlaveOk
MongoDB 系列教程索引 : MongoDB 教程索引 (附有视频)
上一篇: MongoDB 教程五: MongoDB固定集合和性能优化
下一篇: MongoDB 教程六: MongoDB管理:数据导入导出,数据备份恢复及用户安全与认证
本文:MongoDB 教程五: MongoDB固定集合和性能优化 (索引Indexes, 优化器, 慢查询profile)
![]()

Node.js: exports 和 module.exports 的区别
PHP: 创建数字的缩写, How to create the abbreviation of a number in PHP
